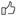应用程序的架构模式主要分为两种 : C / S ( 客户端 / 服务器端 ) 和B / S ( 浏览器 / 服务器端 ) .
* 1. C / S模式 , 即客户端 / 服务器模式 ( Client / Server Model ) : 是一种分布式计算模式 .
它将应用程序的功能划分为客户端和服务器端两部分 .
在这种模式下 , 客户端通常负责提供用户界面 , 处理用户输入和显示输出 ,
而服务器端则负责处理核心的业务逻辑 , 数据存储和访问控制等任务 .
* 2. B / S模式 , 即浏览器 / 服务器端模式 ( Browser / Server Model ) : 是一种基于Web的分布式计算框架 .
它将应用程序的功能划分为浏览器端和服务器端两部分 .
在这种框架下 , 用户通过Web浏览器作为客户端来访问和交互服务器端的应用程序 .
在B / S框架中 , 浏览器端主要负责提供用户界面 , 展示从服务器端接收到的数据和响应 .
它通常包括HTML页面 , CSS样式表和JavaScript脚本等前端技术 , 以创建丰富的用户界面和交互体验 .
浏览器端处理用户输入 , 例如点击按钮 , 填写表单等 , 并将这些输入通过HTTP请求发送到服务器端 .
服务器端则负责处理核心的业务逻辑 , 数据存储和访问控制等任务 .
它接收来自浏览器端的HTTP请求 , 并根据请求的内容执行相应的业务逻辑操作 .
服务器端可以与数据库进行交互 , 存储和检索数据 , 以满足用户请求的需求 .
然后 , 服务器端将处理结果以HTML页面 , JSON数据或XML数据等格式发送给浏览器端进行展示 .
C / S架构 , 在计算机历史的长河中持续保持其重要地位 , 其优点如下 :
* 1. 客户端和服务器直接相连 .
更高的安全性 : 客户端和服务器直接相连 , 采用点对点的通信模式 , 可以减少中间环节带来的安全风险 , 从而提高数据传输的安全性 .
直接操作本地资源 : 客户端直接访问和操作本地资源 , 如 : 数据库等 , 这大大减少了获取资源的时间和精力 , 提高了工作效率 .
减少通信流量和成本 : 由于直接相连 , 减少了中间转发和路由的环节 , 从而降低了通信流量 , 对于客户来说可以节约网络使用费用 .
响应速度快 : 直接相连减少了通信延迟 , 使得客户端和服务器之间的响应速度更快 ,
特别是在处理大量数据或复杂业务逻辑时 , 这种优势尤为明显 .
* 2. 客户端可以处理一些逻辑事务 .
充分利用硬件资源 : C / S架构允许客户端和服务器各自处理部分逻辑事务 , 从而充分利用两者的硬件资源 , 避免资源的浪费 .
分担服务器负载 : 客户端可以分担一部分数据处理和数据存储的任务 , 从而减轻服务器的负担 , 提高系统的整体性能 .
处理复杂事务流程 : 客户端可以处理复杂的业务逻辑和事务流程 , 如数据验证 , 用户交互等 , 使得整个系统更加灵活和高效 .
强大的功能和用户体验 : 客户端通常拥有完整的应用程序界面和丰富的功能 , 如出错提示 , 在线帮助等 , 可以提供更好的用户体验和支持 .
* 3. 客户端操作界面 .
提高视觉体验 : C / S架构允许客户端拥有自定义的操作界面 , 可以根据用户需求进行个性化设计 , 提高用户的视觉体验 .
满足个性化需求 : 客户端操作界面可以随意排列和配置 , 充分满足用户的个性化需求 , 展现不同的特点和个性 .
丰富的交互方式 : 客户端操作界面通常提供丰富的交互方式 , 如菜单 , 按钮 , 文本框等 , 使得用户可以更加方便地进行操作和控制。
B / S架构 , 在现代企业中广受欢迎 , 特别是在广域网环境中 , 其优点如下 :
* 1. 广泛的访问性 .
标准的通信协议 : 采用Internet上标准的通信协议 ( 如TCP / IP ) 作为客户机与服务器通信的基础 ,
使得任何位置的用户都能无障碍地访问服务器资源 .
高效的数据处理与共享 : 服务器提供Web服务和数据库服务 , 高效处理数据 , 并通过标准协议实现数据共享 .
* 2. 简化的数据处理流程 .
集中处理 : 数据处理主要集中在服务器端进行 , 大大简化了客户端的数据处理任务 .
快速响应 : 服务器根据用户请求处理数据 , 生成网页供客户端直接下载和展示 , 提高了系统的整体性能和响应速度 .
* 3. 简化的客户端需求 .
浏览器作为客户端 : 用户不再需要为客户端单独编写和安装其他类型的应用程序 , 只需安装内置浏览器的软件即可访问服务器数据 .
降低复杂性 : 降低了客户端的复杂性 , 减少了用户的学习和维护成本 .
良好的通用性和兼容性 : 由于浏览器是计算机的标准设备 , B / S架构具有很好的通用性和兼容性 .
Web应用程序 ( Web Application ) : 是一种可以通过Web浏览器访问的应用程序 , 它遵循浏览器 / 服务器 ( Browser / Server , 简称B / S ) 架构 .
在开发Web应用程序时 , 通常会使用后端技术 ( 如Java , Python , Ruby , PHP等 ) 来处理服务器端逻辑和数据存储 ,
以及前端技术 ( 如HTML , CSS , JavaScript等 ) 来构建用户界面和提供用户交互 .
此外 , 还会使用数据库技术 ( 如MySQL , PostgreSQL , MongoDB等 ) 来存储和管理应用程序的数据 .
以下是Web应用程序的一些特点 :
* 1. 可扩展性 : Web应用程序可以通过添加更多的服务器和负载均衡器来扩展其处理能力 , 以满足更多的用户请求 .
* 2. 安全性 : Web应用程序可以通过使用HTTPS协议 , 身份验证 , 授权和加密技术来确保数据传输和存储的安全性 .
* 3. 交互性 : Web应用程序通常使用HTML , CSS , JavaScript等前端技术来提供丰富的用户交互体验 ,
如表单输入 , 动态内容更新 , 动画效果等 .
以下是Web应用程序的一些优点 :
* 1. 便捷性 : Web应用程序无需复杂的安装过程 .
用户只需拥有一个合适的浏览器 , 即可随时随地访问应用程序 , 极大地提高了使用的便捷性 .
* 2. 节省硬盘空间 : 与传统的桌面应用程序相比 , Web应用程序通常几乎不占用或仅占用极少的用户硬盘空间 .
这是因为应用程序的主要数据和功能都存储在服务器上 , 用户端仅加载所需的界面和交互组件 .
* 3. 自动更新 : Web应用程序无需用户手动更新 .
一旦服务器上的应用程序进行了更新或添加了新特性 , 用户在下一次访问时就会自动接收到这些更新 .
这不仅简化了用户操作 , 也确保了所有用户都能享受到最新的功能和安全修复 .
* 4. 易于集成 : Web应用程序可以与其他Web服务 ( 如数据库 , API , 第三方服务等 ) 进行集成 , 以实现更复杂的功能和数据交换 .
这种集成能力使得Web应用程序能够提供更丰富 , 更全面的服务 , 满足用户的多样化需求 .
* 5. 跨平台性 : 由于Web应用程序在网络浏览器窗口中运行 , 它们通常能够跨多个操作系统和平台使用 .
这意味着无论用户使用的是Windows , Mac , Linux还是其他操作系统 ,
都能获得一致的使用体验 , 极大地提高了应用程序的普适性和可访问性 .
以下是Web应用程序的一些缺点 :
* 1. 浏览器兼容性 : Web应用程序高度依赖浏览器的适用性 .
如果浏览器不支持特定的功能 , 或者停止支持某些较旧的平台或操作系统版本 , 将直接影响大量用户的使用体验 .
* 2. 网络连接依赖性 : 由于Web应用程序运行在远程服务器上 , 一旦网络连接出现问题 , 应用程序将无法正常使用 , 这给用户带来了很大的不便 .
* 3. 定制化与个性化受限 : 许多Web应用程序不是开源的 , 用户只能依赖第三方提供的服务 , 因此难以进行个性化的定制和修改 .
同时 , 由于依赖在线服务 , 用户通常无法离线使用这些应用程序 , 限制了其使用的灵活性 .
* 4. 服务商的可及性风险 : Web应用程序完全依赖于应用服务商的运营 .
如果公司倒闭或服务器停止使用 , 用户将无法访问以前的数据 , 这带来了数据丢失的风险 .
相比之下 , 传统安装的软件即使制造商倒闭 , 用户仍可以继续使用 , 尽管可能无法获得更新或用户支持 ( 联网变单机 ) .
* 5. 服务商控制权过大 : 服务商对Web应用程序及其功能拥有更大的控制权 .
他们可以随意添加新特性 , 即使这些特性并不符合用户的需求或期望 .
此外 , 服务商还可以在不通知用户的情况下减少服务带宽以削减成本 , 从而影响用户体验 .
* 6. 隐私安全问题 : 由于Web应用程序需要收集和处理用户数据 , 服务商理论上可以检索和分析用户的任何行为 .
这引发了用户对隐私安全的担忧 , 尤其是在缺乏有效监管和透明度的环境中 .
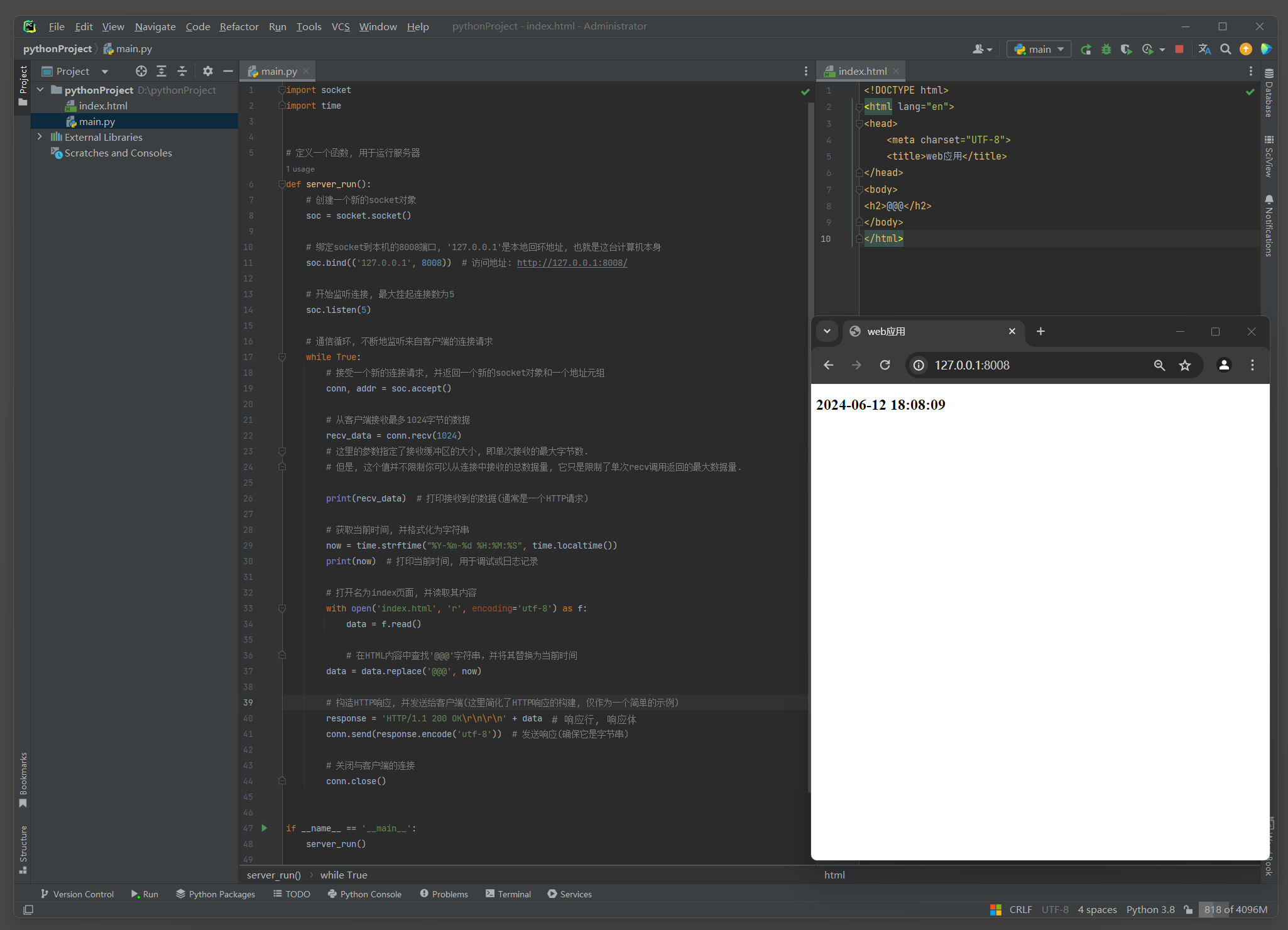
构建一个简易的HTTP服务器 , 借助Python的socket库来实现网络监听功能 , 并处理来自客户端的连接请求 , 从而提供HTTP响应服务 .
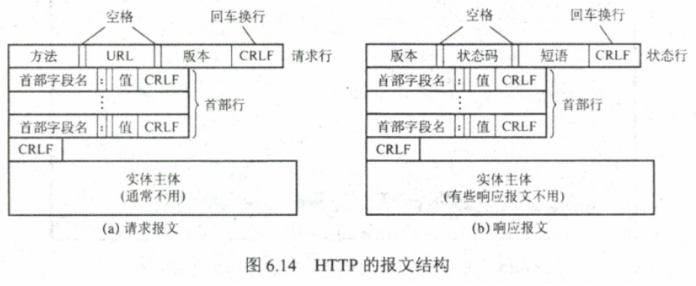
要通过HTTP协议发送响应给客户端 ( 例如一个Web浏览器 ) 时 , 需要确保你遵循了HTTP协议的格式 .
HTTP响应由 : 状态行 ( HTTP / 1.1 200 OK ) , 响应头 ( 目前空着 ) 和响应体组成 , 响应体紧跟在响应头之后 , 用两个 \ r \ n来分隔响应头和响应体 .
例如 : HTTP / 1.1 200 OK \ r \ n \ r \ n 响应体 .
访问服务端地址 : http : / / 127.0 .0 .1 : 8008 /, 返回index页面 , 页面中当前时间 .
import socket
import time
def server_run ( ) :
soc = socket. socket( )
soc. bind( ( '127.0.0.1' , 8008 ) )
soc. listen( 5 )
while True :
conn, addr = soc. accept( )
recv_data = conn. recv( 1024 )
print ( recv_data)
now = time. strftime( "%Y-%m-%d %H:%M:%S" , time. localtime( ) )
print ( now)
with open ( 'index.html' , 'r' , encoding= 'utf-8' ) as f:
data = f. read( )
data = data. replace( '@@@' , now)
response = 'HTTP/1.1 200 OK\r\n\r\n' + data
conn. send( response. encode( 'utf-8' ) )
conn. close( )
if __name__ == '__main__' :
server_run( )
编写服务器读取的前端页面 .
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h2> </ h2> </ body> </ html> 启动服务端 , 访问 : 127.0 .0 .1 : 8008 , 访问成功后 , 读取一个HTML文件 ( index . html ) , 在其中找到字符串 '@@@' , 并将其替换为当前时间 .
# 第一次访问根路径 ( / ) .
b ' GET / HTTP / 1.1 \ r \ n
Host : 127.0 .0 .1 : 8008 \ r \ n
Connection : keep-alive \ r \ n
sec-ch-ua : "Google Chrome" ; v = "125" , "Chromium" ; v = "125" , "Not.A/Brand" ; v = "24" \ r \ n
sec-ch-ua-mobile : ? 0 \ r \ n
sec-ch-ua-platform : "Windows" \ r \ n
Upgrade-Insecure-Requests : 1 \ r \ n
User-Agent : Mozilla / 5.0 ( Windows NT 10.0 ; Win64 ; x64 )
AppleWebKit / 537.36 ( KHTML , like Gecko ) Chrome / 125.0 .0 .0 Safari / 537.36 \ r \ n
Accept : text / html , application / xhtml + xml , application / xml ; q = 0.9 , image / avif ,
image / webp , image / apng , * / * ; q = 0.8 , application / signed-exchange ; v = b3 ; q = 0.7 \ r \ n
Sec-Fetch-Site : none \ r \ nSec-Fetch-Mode : navigate \ r \ n
Sec-Fetch-User : ? 1 \ r \ nSec-Fetch-Dest : document \ r \ n
Accept-Encoding : gzip , deflate , br , zstd \ r \ n
Accept-Language : en , zh-CN ; q = 0.9 , zh ; q = 0.8 \ r \ n
Cookie : sessionid = xqu7m1ffngra339r34i9sh44zsk3hcll \ r \ n \ r \ n '
# 第二次访问 / favicon . ico , 获取网站图标 ( 页面自动发送的请求 ) .
b ' GET / favicon . ico HTTP / 1.1 \ r \ n
Host : 127.0 .0 .1 : 8008 \ r \ nConnection : keep-alive \ r \ n
sec-ch-ua : "Google Chrome" ; v = "125" , "Chromium" ; v = "125" , "Not.A/Brand" ; v = "24" \ r \ n
sec-ch-ua-mobile : ? 0 \ r \ n
User-Agent : Mozilla / 5.0 ( Windows NT 10.0 ; Win64 ; x64 )
AppleWebKit / 537.36 ( KHTML , like Gecko ) Chrome / 125.0 .0 .0 Safari / 537.36 \ r \ n
sec-ch-ua-platform : "Windows" \ r \ n
Accept : image / avif , image / webp , image / apng , image / svg + xml , image / * , * / * ; q = 0.8 \ r \ n
Sec-Fetch-Site : same-origin \ r \ n
Sec-Fetch-Mode : no-cors \ r \
nSec-Fetch-Dest : image \ r \ n
Referer : http : / / 127.0 .0 .1 : 8008 /\r\n
Accept-Encoding : gzip , deflate , br , zstd \ r \ n
Accept-Language : en , zh-CN ; q = 0.9 , zh ; q = 0.8 \ r \ n
Cookie : sessionid = xqu7m1ffngra339r34i9sh44zsk3hcll \ r \ n \ r \ n '
请求头是从GET / HTTP / 1.1 \ r \ n开始 , 一直到最后的空行 \ r \ n \ r \ n之前 .
空行 \ r \ n \ r \ n之后是请求体 , 但在GET请求中 , 请求体通常是空的 .
在POST或PUT等请求中 , 请求体会包含发送到服务器的数据 .
例子中 , 服务器代码读取了请求数据 ( 虽然它只读取了前 1024 个字节 , 但在这个请求的情况下应该足够了 ) , 下面是对请求信息的简单解释 :
* 1. GET / HTTP / 1.1 : 这是一个HTTP GET请求 , 请求的资源路径是根路径 ( / ) , 使用的HTTP协议版本是 1.1 .
* 2. Host : 127.0 .0 .1 : 8008 : 请求的目标主机是 127.0 .0 .1 ( 本地主机 ) , 端口是 8008.
* 3. Connection : keep-alive : 客户端希望保持这个TCP连接 , 以便后续可以复用 , 而不是每次请求都建立一个新的连接 .
* 4. sec-ch-ua , sec-ch-ua-mobile , sec-ch-ua-platform等 :
这些是Google Chrome和其他基于Chromium的浏览器用来发送用户代理信息的字段 , 以便网站可以根据这些信息优化内容或行为 .
* 5. DNT : 1 : 表示客户端不希望被追踪 ( Do Not Track ) .
* 6. Upgrade-Insecure-Requests : 1 : 如果服务器上有更安全的版本 ( 比如HTTPS ) , 客户端希望自动升级到那个版本 .
* 7. User-Agent : 这是一个字符串 , 描述了发出请求的客户端 ( 比如浏览器 ) 的类型 , 版本 , 操作系统等信息 .
* 8. Accept : 客户端可以接受的媒体类型 ( 比如HTML , XML , 图片等 ) .
* 9. Sec-Fetch-Site , Sec-Fetch-Mode , Sec-Fetch-User , Sec-Fetch-Dest :
这些是浏览器发送的安全相关的请求头 , 用于防止跨站请求伪造 ( CSRF ) 等攻击 .
* 10. Accept-Encoding : 客户端可以接受的编码方式 ( 比如gzip压缩 ) .
* 11. Accept-Language : 客户端首选的语言 .
* 12. Cookie : 如果客户端之前与服务器建立了会话 , 它可能会发送一个或多个cookie , 用于会话跟踪或身份验证 .
request_data = b''
while True :
data = client_socket. recv( 1024 )
if not data:
break
request_data += data
favicon . ico图标用于收藏夹图标和浏览器标签上的显示 ,
一般浏览器会请求网站根目录的这个图标 , 如果网站根目录也没有这图标会返回 404.
网站图标 ( 通常也被称为favicon或网站LOGO ) 的大小和尺寸可以根据不同的用途和设计需求而有所不同 .
最小的图标尺寸通常是 16 x16像素 . 这种尺寸的图标经常用于显示在浏览器的标签页上 , 或者在某些操作系统中显示在浏览器的书签栏中 .
出于优化的考虑 , 要么就有这个图标 , 要么就禁止产生这个请求 .
禁止方式 : 在html页面的 < head > 区域 , 加上如下代码实现屏蔽 .
< link rel = "icon" type = "image/x-icon" href = "data:image/x-icon;base64, 无效的Base64编码..." >
在这个特定的例子中 , 该标签的href属性使用了一个数据URI ( Data URI ) 来尝试加载一个图标 , 但实际上并没有提供任何有效的图标数据 .
rel = "icon" : 指定了链接的关系类型 , 即这个链接是一个图标 .
href = "data:;base64, 无效的Base64编码..." : 这里使用了数据URI来尝试直接嵌入图标数据 .
但是 , base64 , 后面没有跟随任何有效的Base64编码的数据 , 所以实际上这个链接指向了一个空的数据源 .
想要使用请查看base64作为图标 :
https : / / blog . csdn . net / qq_46137324 / article / details / 139640131 ?spm = 1001.2014 .3001 .5502
基于请求的URI部分 ( 即 / index / 路 ) 来决定如何响应 .
例如 : 用户访问 : 127.0 .0 .1 : 8080 /index/ , 后端获取请求地址返回特定的HTML页面 .
思路逻辑描述 :
* 1. 接收并解析请求 .
1.1 服务端从客户端接收HTTP请求 .
1.2 请求数据通常是二进制格式的 , 但在处理时 , 服务器会将其解析为文本格式 .
1.3 提取URI路径 : 从请求行中提取URI部分 ( 即 / index / ) .
* 2. 响应判断 : 判断提取出的URI路径是否与想要响应的路径 ( 在这种情况下是 / index / ) 匹配 .
如果匹配 , 执行相应的处理逻辑 ( 如发送特定的HTML页面 , JSON数据或其他资源 ) .
* 3. 构建并发送响应 : 根据URI路径的匹配结果 , 构建HTTP响应并将响应发送回客户端 .
当浏览器发送一个HTTP请求时 , 它发送的是一个按照HTTP协议格式组织的文本字符串 .
然而 , 当这个字符串通过TCP / IP协议栈在网络中传输时 , 它确实以字节 ( 即二进制形式 ) 发送的 .
在服务器端 , 套接字 ( socket ) 读取数据时 , 会得到一个字节串 ( bytes ) , 这个字节串是HTTP请求的原始二进制表示 .
需要将这些字节解码为字符串 , 以便能够解析和处理HTTP请求的各个部分 .
对于HTTP / 1.1 , 规范 ( RFC 2616 ) 明确提到 :
请求行 , 状态行和头部字段中的字段名 ( Field Name ) 必须是ASCII字符 .
头部字段中的字段值 ( Field Value ) 可以是任何字符集 , 但通常建议使用ASCII或ISO- 8859 - 1 , 除非有特定的内容类型需要其他编码 ( 如UTF- 8 ) .
请求体和响应体中的编码方式取决于Content-Type头部字段中的charset参数 .
如果没有指定charset参数 , 则默认可能依赖于上下文或应用层协议 ( 对于许多现代Web应用 , 默认使用UTF- 8 编码是常见的做法 ) .
涉及两种编码 : ASCII与UTF- 8.
为了兼容性和健壮性 , 使用UTF- 8 解码是可行的 , 因为UTF- 8 是ASCII的超集 , 并且可以正确地解码所有ASCII字符 .
b'GET / HTTP/1.1\r\nHost: 127.0.0.1:8000\r\n.....'
GET / HTTP/ 1.1
Host: 127.0 .0 .1 : 8000
. . .
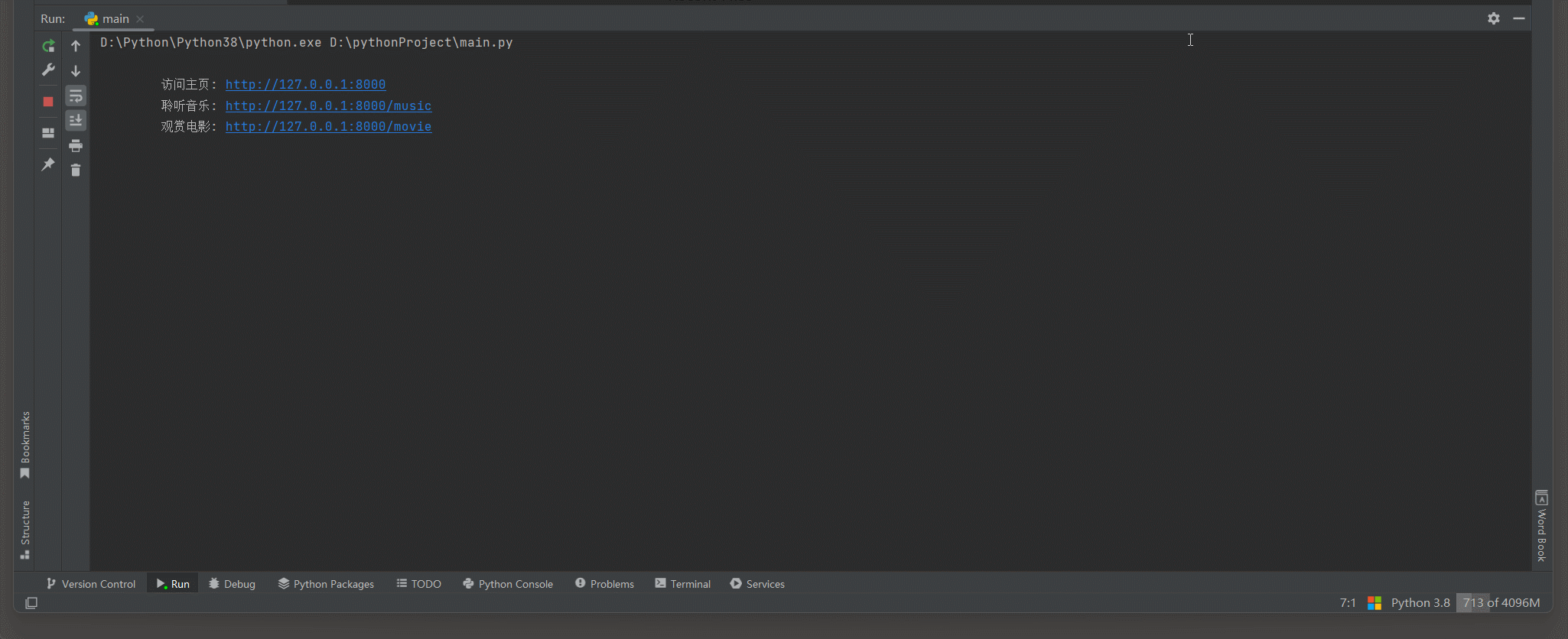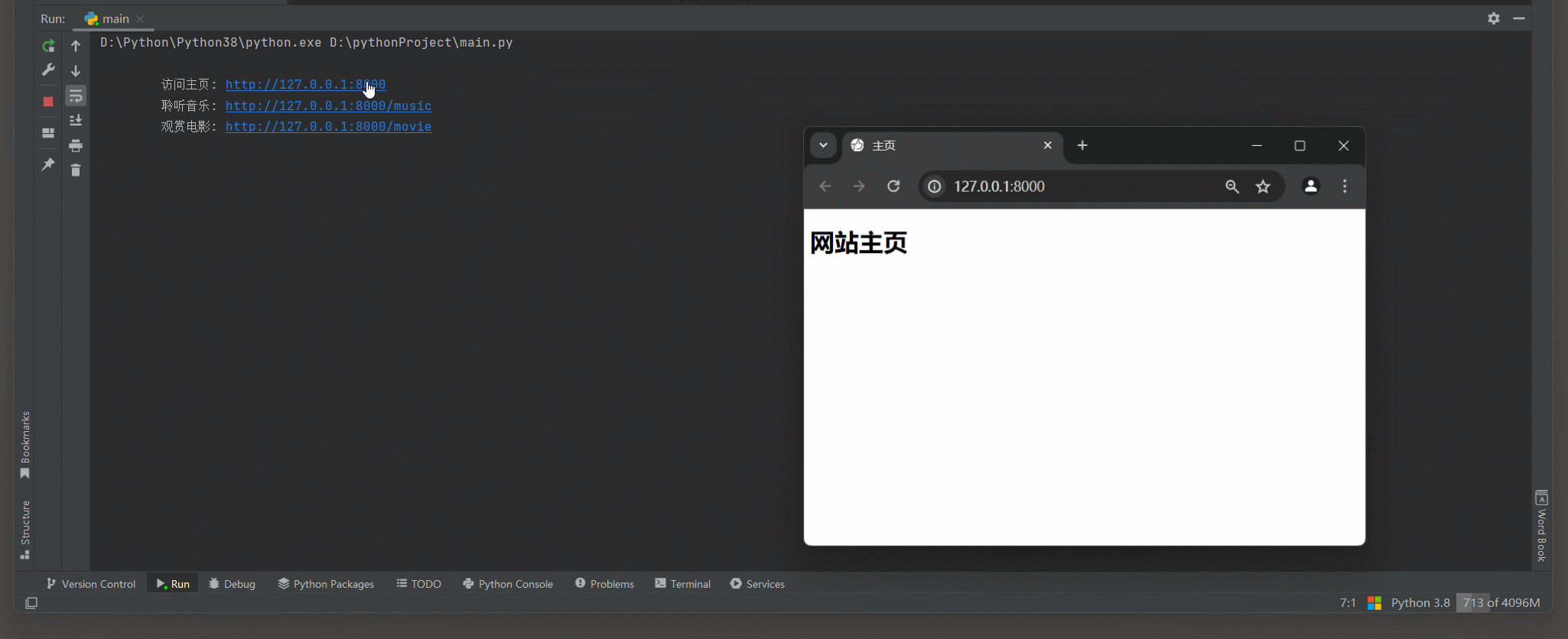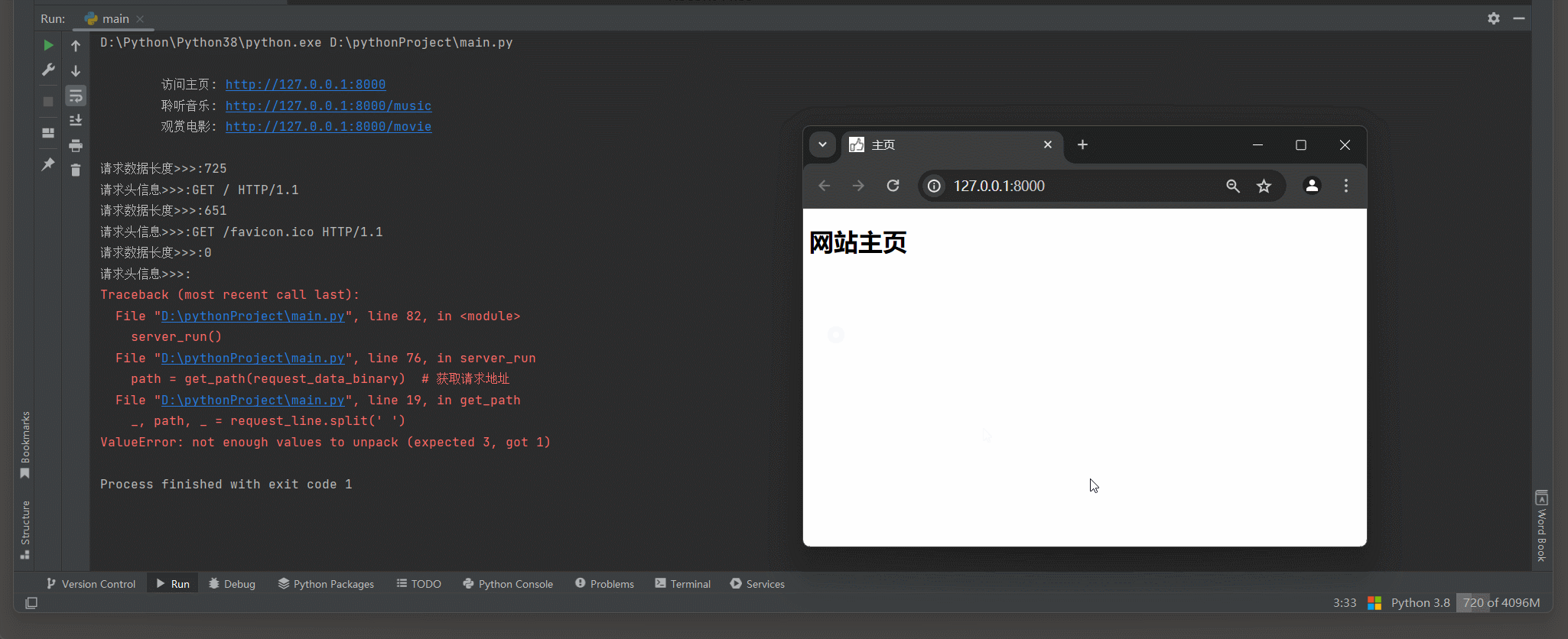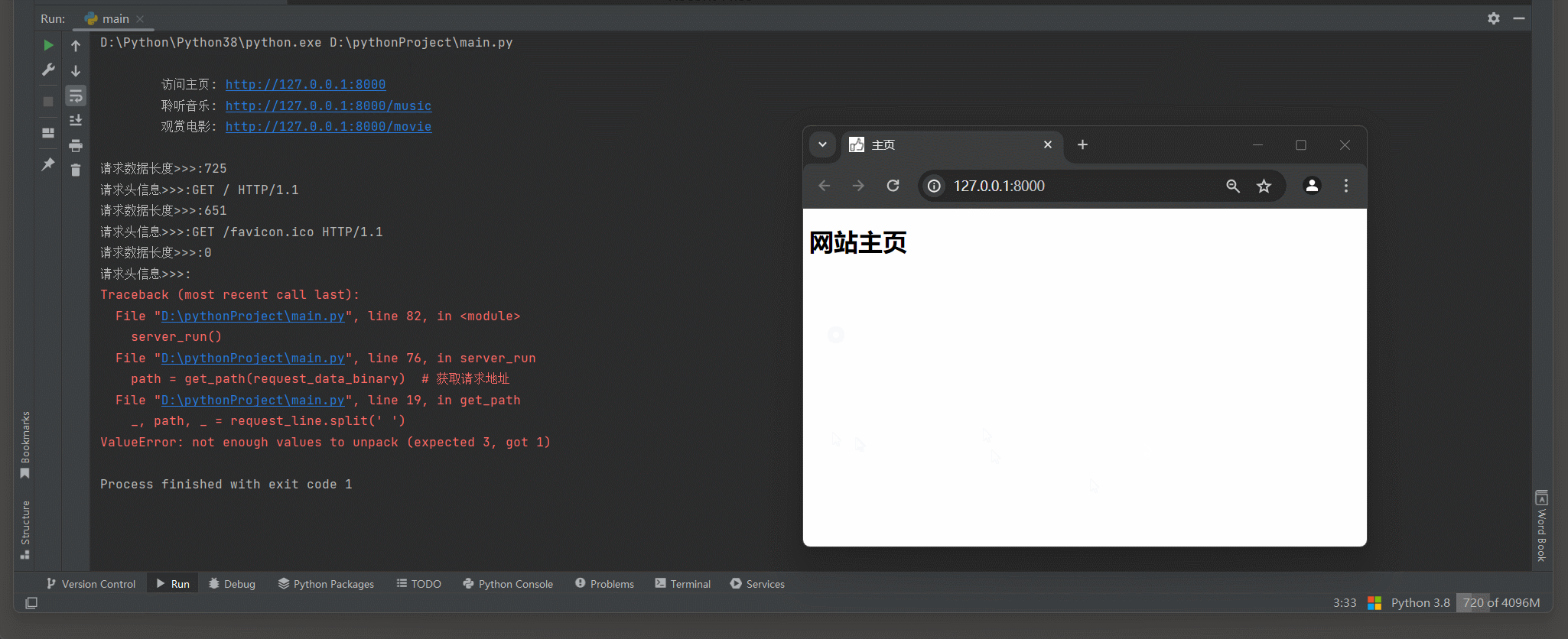
在Web开发中 , "index页面" , "home页面" 和 "/" 页面经常会被提到 , 它们通常指的是网站的主要入口点或起始页 .
虽然这些术语有时可以互换使用 , 但它们在某些上下文中可能有细微的差别 .
以下是对这三个术语的解释 :
* 1. index页面 : 通常指的是一个网站目录中的默认页面 , 当访问一个目录时没有指定具体文件名时 , 服务器会自动提供该目录下的index页面 . 例如 , 在Apache或Nginx等Web服务器上 , 默认的index页面可能是index . html , index . htm , index . php等
在很多情况下 , index页面就是一个网站的home页面 , 但并非总是如此 .
* 2. home页面 : 指的是网站的主页 , 即用户访问网站时看到的第一个页面 .
它通常是网站的起点 , 提供了网站内容的概览 , 导航到其他页面的链接以及网站的主要功能和信息 .
在很多网站架构中 , home页面与index页面是同一个页面 , 但也有可能不是 .
例如 , 一个复杂的网站可能有一个单独的home页面设计 , 而index页面只是一个简单的引导页或者登录页 .
* 3. "/" 页面 : 在Web开发中 , "/" 通常代表网站的根URL . 当用户访问网站的根URL时 , 服务器通常会提供index页面或home页面 .
在许多Web框架和CMS ( 内容管理系统 ) 中 , "/" 路由或路径默认映射到home页面或index页面 .
目录结构如下 :
Project :
| -- 404. html
| --favicon . ico
| --music . html
| --index . html
| --main . py
| --movie . html
图标 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> </ body> </ html>
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> </ body> </ html>
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> </ body> </ html>
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> </ body> </ html>
import socket
def get_path ( binary_response) :
str_request = binary_response. decode( 'UTF-8' )
request_line = str_request. split( '\r\n' ) [ 0 ]
print ( f'请求头信息>>>: { request_line} ' )
_, path, _ = request_line. split( ' ' )
return path
def response_body ( file_name) :
with open ( file_name, 'rb' ) as f:
binary_html = f. read( )
return binary_html
def match_path ( path, conn) :
html_dict = {
'/' : 'index.html' ,
'/music' : 'music.html' ,
'/movie' : 'movie.html' ,
'/favicon.ico/' : 'favicon.ico'
}
if path in html_dict:
binary_html = response_body( html_dict. get( path) )
else :
binary_html = response_body( '404.html' )
"""
先发响应头再发信息
http特性:当数据量比较小且时间间隔比较短的多次数据,
那么TCP会自动打包成一个数据包发送.
"""
conn. send( b'HTTP/1.1 200 ok\r\n\r\n' )
conn. send( binary_html)
conn. close( )
def server_run ( ) :
soc = socket. socket( )
soc. bind( ( '127.0.0.1' , 8000 ) )
soc. listen( 5 )
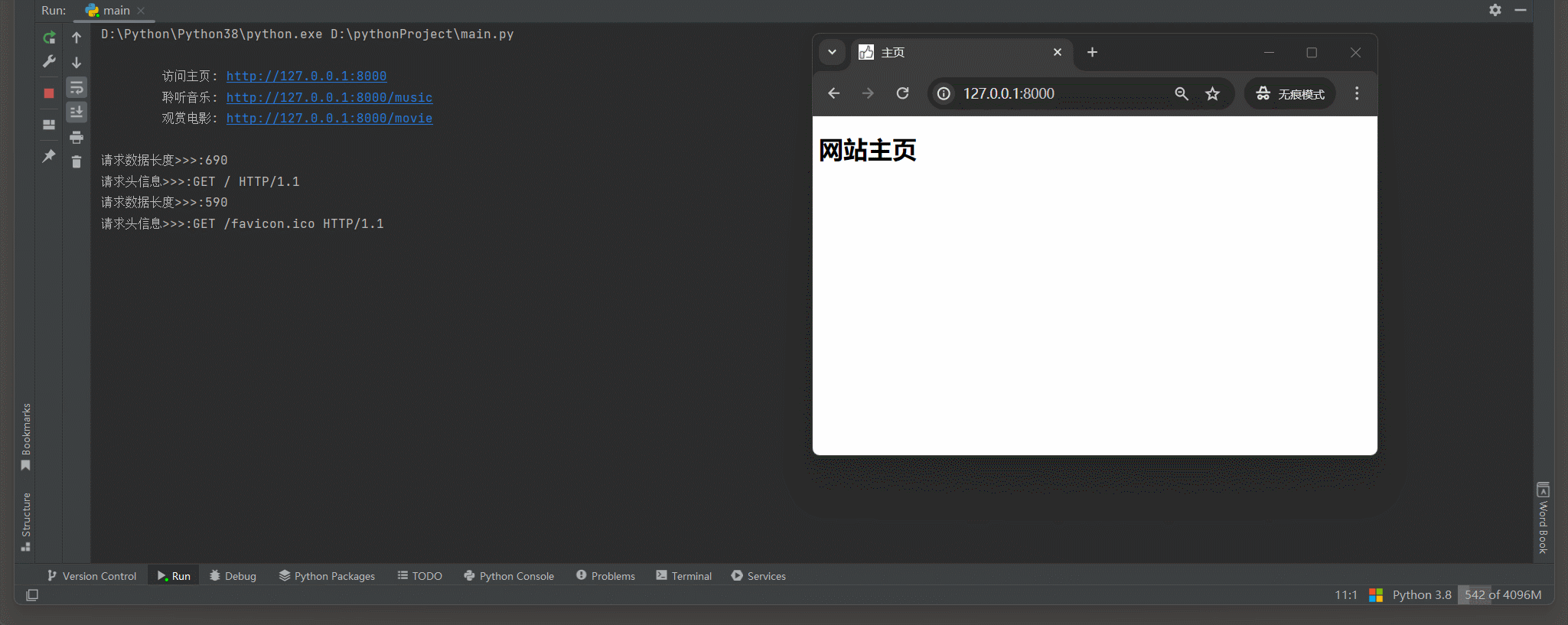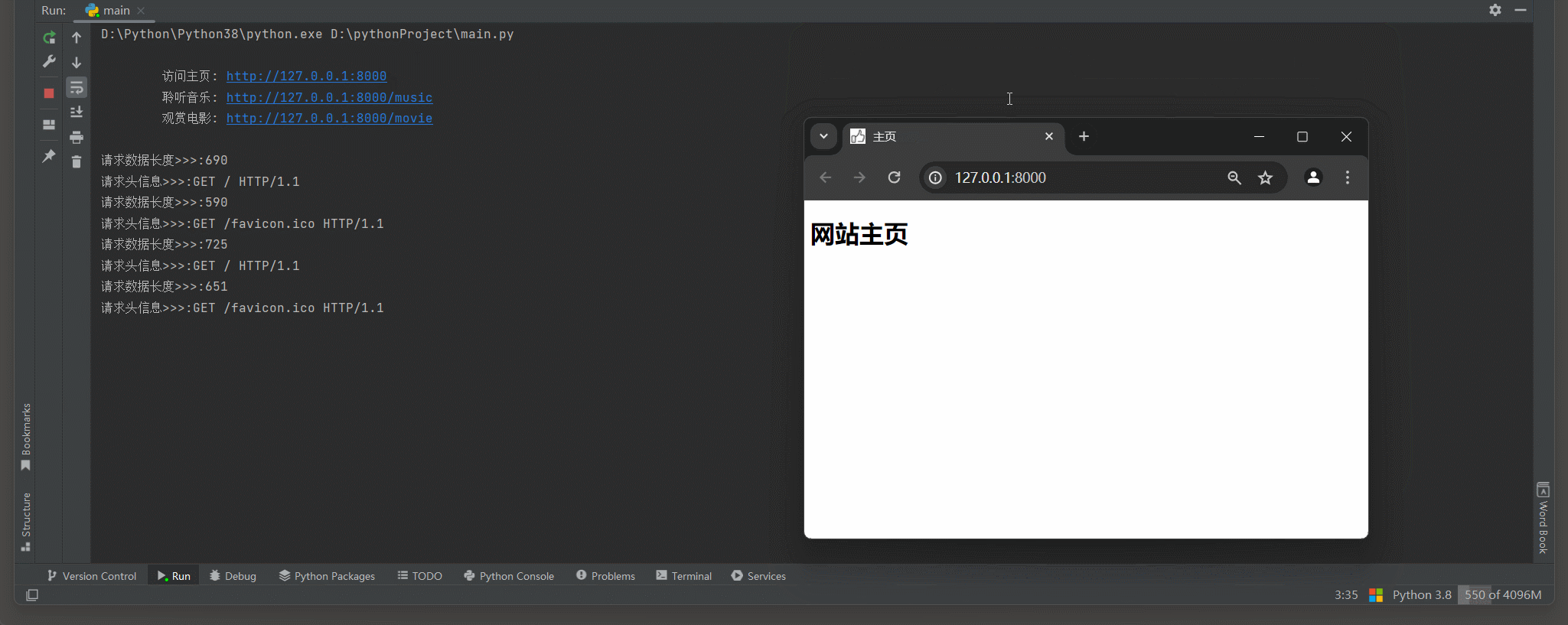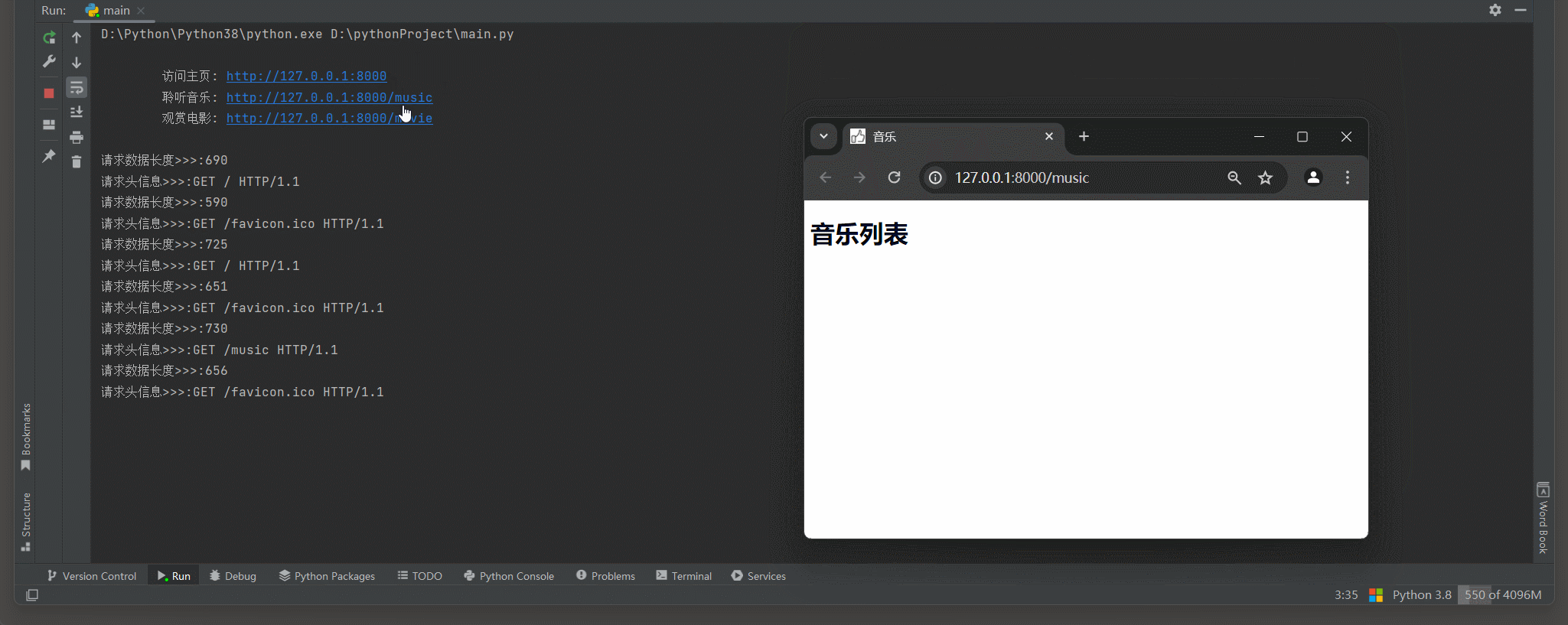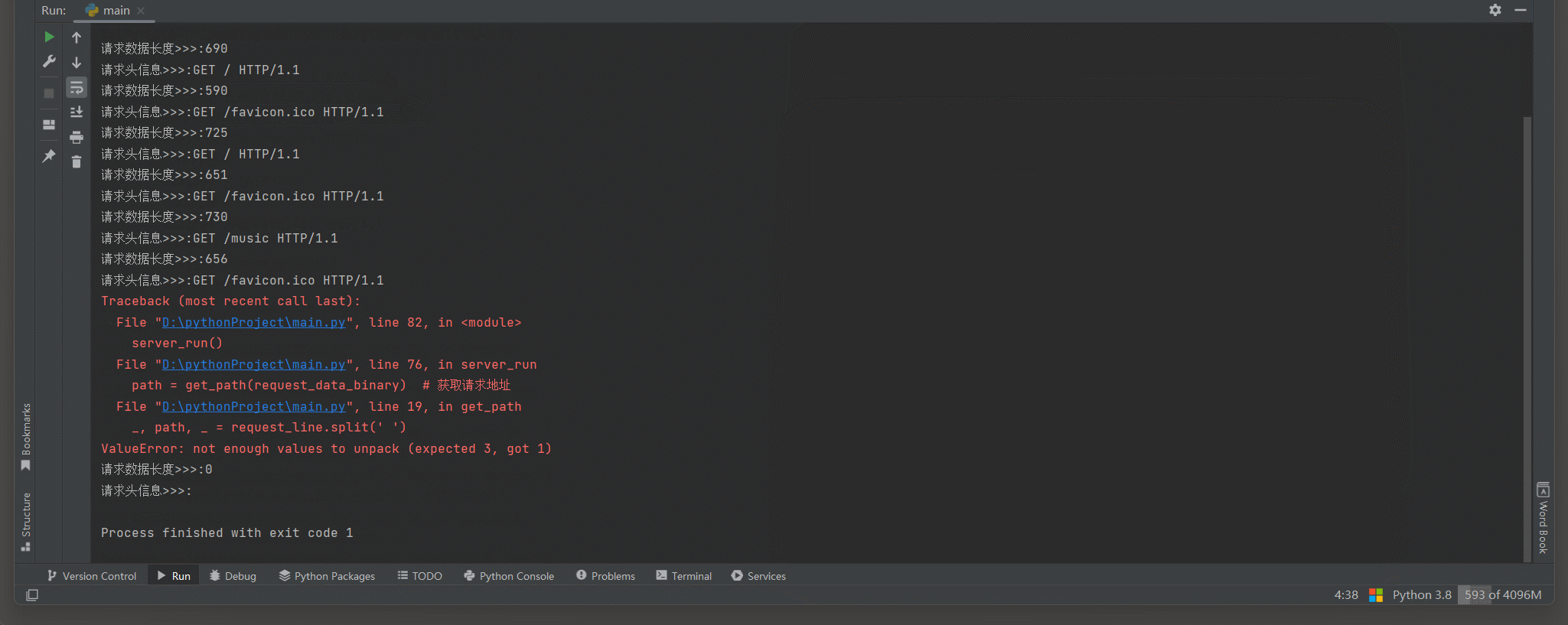
print (
"""
访问主页: http://127.0.0.1:8000
聆听音乐: http://127.0.0.1:8000/music
观赏电影: http://127.0.0.1:8000/movie
""" )
while True :
conn, addr = soc. accept( )
request_data_binary = conn. recv( 1024 )
print ( f'请求数据长度>>>: { len ( request_data_binary) } ' )
path = get_path( request_data_binary)
match_path( path, conn)
if __name__ == '__main__' :
server_run( )
遇到以下两种情况 :
* 1. 正常访问的时候多出一个空请求 .
* 2. 关闭网页的时候多出一个空请求 .
TCP 连接已关闭 : 当客户端正常关闭TCP连接时 , 服务器端的recv ( ) 调用可能会返回一个空字节串 ( b '' ) ,
表示没有更多的数据可以读取 , 并且连接已经被关闭 .
但是 , 这并不是一个可靠的信号 , 因为recv ( ) 也可以在其他情况下返回空字节串 , 比如当没有数据可读时 .
客户端 ( 可能是浏览器 ) 在发送了 / favicon . ico请求后关闭了连接 , 通样可能会出现上述问题 .
( 是可能 , 不是百分百出现 )
解决方案 : 获取请求数据的时候 , 对数据进行判断 , 如果请求行为空字节串 , 那么可以确认连接已经被对方关闭 .
则关闭连接 , 跳过本次循环 .
request_data_binary = conn. recv( 1024 )
if not len ( request_data_binary) :
conn. close( )
continue
import socket
def get_path ( binary_response) :
str_request = binary_response. decode( 'UTF-8' )
request_line = str_request. split( '\r\n' ) [ 0 ]
print ( f'请求头信息>>>: { request_line} ' )
_, path, _ = request_line. split( ' ' )
return path
def response_body ( file_name) :
with open ( file_name, 'rb' ) as f:
binary_html = f. read( )
return binary_html
def match_path ( path, conn) :
html_dict = {
'/' : 'index.html' ,
'/music' : 'music.html' ,
'/movie' : 'movie.html' ,
'/favicon.ico/' : 'favicon.ico'
}
if path in html_dict:
binary_html = response_body( html_dict. get( path) )
else :
binary_html = response_body( '404.html' )
conn. send( b'HTTP/1.1 200 ok\r\n\r\n' )
conn. send( binary_html)
conn. close( )
def server_run ( ) :
soc = socket. socket( )
soc. bind( ( '127.0.0.1' , 8000 ) )
soc. listen( 5 )
print (
"""
访问主页: http://127.0.0.1:8000
聆听音乐: http://127.0.0.1:8000/music
观赏电影: http://127.0.0.1:8000/movie
""" )
while True :
conn, addr = soc. accept( )
request_data_binary = conn. recv( 1024 )
if not len ( request_data_binary) :
conn. close( )
continue
print ( f'请求数据长度>>>: { len ( request_data_binary) } ' )
path = get_path( request_data_binary)
match_path( path, conn)
if __name__ == '__main__' :
server_run( )
wsgiref是Python标准库中的一个模块 , 它实现了Web服务器网关接口 ( WSGI , Web Server Gateway Interface ) 的规范和实用程序 .
WSGI是一个为Python语言定义的Web服务器和Web应用程序或框架之间的简单而通用的接口 .
wsgiref模块提供了WSGI工具 , 服务器和中间件组件 , 它们对于开发 , 测试或理解WSGI应用程序和服务器非常有用 .
wsgiref模块的主要作用 :
* 1. 解析HTTP请求 : 当HTTP请求到达时 , wsgiref或其他WSGI服务器会解析该请求 ( 包括方法 , 路径 , 查询参数 , 头部等 ) ,
并将这些解析后的信息封装成一个字典 ( 通常称为environ字典 ) 和一个输入流 ( 通常用于读取请求体 ) .
这个字典和流会作为参数传递给WSGI应用程序 .
environ字典包含了大量的关于请求的信息 , 如客户端的IP地址 , 请求的路径 , 请求头 , 查询参数等 .
这使得开发者可以轻松地访问这些信息 , 而无需直接处理原始的HTTP数据 .
* 2. 响应打包成HTTP格式 : 当WSGI应用程序处理完请求并准备返回响应时 ,
它会返回一个状态码 , 一个响应头字典和一个输出流 ( 用于写入响应体 ) .
wsgiref服务器或其他WSGI服务器会负责将这些信息打包成一个符合HTTP格式的响应 , 并发送给客户端 ( 如浏览器 ) .
* 3. 提供简单的HTTP服务器 : wsgiref . simple_server提供了一个简单的HTTP服务器实现 , 它允许你快速运行和测试WSGI应用程序 .
虽然这个服务器在生产环境中可能不够健壮和高效 , 但对于开发和测试来说非常方便 .
* 4. 中间件支持 : WSGI还支持中间件组件 , 这些组件可以插入到应用程序和服务器之间 ,
用于执行各种任务 , 如身份验证 , 日志记录 , URL重写等 .
wsgiref提供了一些用于构建中间件的实用程序 .
总的来说 , wsgiref模块使得Python开发者能够更容易地理解和使用WSGI接口 , 从而开发出符合标准的Web应用程序和服务器 .
虽然它可能不是生产环境中首选的解决方案 , 但对于学习 , 开发和测试来说 , 它是一个非常有价值的工具 .
下列代码示例展示了如何使用wsgiref . simple_server创建一个简单的WSGI服务器 , 并定义了一个处理请求的run函数 .
添加Content-Type响应头部来指明返回的内容类型是纯文本 , 这样做更符合HTTP协议的标准实践 .
from wsgiref. simple_server import make_server
def wsgi_app ( environ, start_response) :
print ( environ)
status = '200 OK'
headers = [ ( 'Content-Type' , 'text/html' ) ]
start_response( status, headers)
return [ b'Hello, World!' ]
if __name__ == '__main__' :
server = make_server( '127.0.0.1' , 8080 , wsgi_app)
print ( type ( server) )
server. serve_forever( )
由于WSGI要求响应体是字节串 ( byte strings ) , 所以需要确保字符串被正确编码为字节串 .
start_response函数的第一个参数是状态码和状态消息 , 它们之间应该用空格隔开 .
状态消息是 "200 OK" ( 即OK大写 ) , 虽然HTTP状态消息对大小写不敏感 , 但按照惯例 , 它们通常是大写的 .
在WSGI协议中 , wsgi_app函数 ( 通常称为WSGI应用程序函数 ) 需要返回一个可迭代对象 , 该对象包含要发送给客户端的响应体 ( body ) 的内容 .
这个可迭代对象通常是一个字节序列 ( byte sequence ) 的列表或生成器 .
在WSGI协议中 , 直接调用类似start_response ( '200 OK' , [ ] ) 并不会立刻发送HTTP响应给客户端 .
start_response函数的调用是为了设置HTTP响应的状态码和头部 , 但它本身并不负责发送任何数据 .
start_response函数是一个由WSGI服务器提供的回调函数 , 用于通知WSGI应用程序如何开始一个HTTP响应 .
当WSGI应用程序调用response函数时 , 它实际上是在告诉WSGI服务器 : '我准备好了响应的状态码和头部, 你可以开始发送它们了.'
但是 , 这并不意味着响应体也会被立刻发送 .
启动服务端 , 在浏览器中输入 : 127.0 .0 .1 : 8080 .
# 查看终端的信息 :
127.0 .0 .1 - - [ 14 /Jun/ 2024 01 : 58 : 54 ] "GET / HTTP/1.1" 200 12
127.0 .0 .1 - - [ 14 /Jun/ 2024 01 : 58 : 54 ] "GET /favicon.ico HTTP/1.1" 200 12
{ 'ALLUSERSPROFILE' : 'C:\\ProgramData' ,
'APPDATA' : 'C:\\Users\\blue\\AppData\\Roaming' ,
'COMMONPROGRAMFILES' : 'C:\\Program Files\\Common Files' ,
'COMMONPROGRAMFILES(X86)' : 'C:\\Program Files (x86)\\Common Files' ,
'COMMONPROGRAMW6432' : 'C:\\Program Files\\Common Files' ,
'COMPUTERNAME' : 'BLUE' ,
'COMSPEC' : 'C:\\Windows\\system32\\cmd.exe' ,
'DRIVERDATA' : 'C:\\Windows\\System32\\Drivers\\DriverData' ,
'FPS_BROWSER_APP_PROFILE_STRING' : 'Internet Explorer' ,
'FPS_BROWSER_USER_PROFILE_STRING' : 'Default' ,
'GETTEXTCLDRDIR' : 'd:\\Program Files\\gettext-iconv\\lib\\gettext' ,
'HOMEDRIVE' : 'C:' ,
'HOMEPATH' : '\\Users\\blue' ,
'IDEA_INITIAL_DIRECTORY' : 'C:\\Users\\blue\\Desktop' ,
'LOCALAPPDATA' : 'C:\\Users\\blue\\AppData\\Local' ,
'LOGONSERVER' : '\\\\BLUE' ,
'NUMBER_OF_PROCESSORS' : '20' ,
'OS' : 'Windows_NT' ,
'PATH' : ' D : \ \ Python \ \ Python3 . 11 \ \ Scripts \ \ ; D : \ \ Python \ \ Python3 . 11 \ \ ;
D : \ \ Python \ \ Python38 \ \ Scripts \ \ ;
D : \ \ Python \ \ Python38 \ \ ;
D : \ \ Python \ \ Python36 \ \ Scripts \ \ ;
D : \ \ Python \ \ Python36 \ \ ;
C : \ \ Windows \ \ system32 ;
C : \ \ Windows ;
C : \ \ Windows \ \ System32 \ \ Wbem ;
C : \ \ Windows \ \ System32 \ \ WindowsPowerShell \ \ v1 . 0 \ \ ;
C : \ \ Windows \ \ System32 \ \ OpenSSH \ \ ;
; d : \ \ Program Files \ \ gettext-iconv \ \ bin ;
D : \ \ Program Files \ \ Redis \ \ ' ,
'PATHEXT' : '.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC;.PY;.PYW' ,
'PROCESSOR_ARCHITECTURE' : 'AMD64' ,
'PROCESSOR_IDENTIFIER' : ' Intel64 Family 6 Model 154 Stepping 3 ,
GenuineIntel ' ,
'PROCESSOR_LEVEL' : '6' ,
'PROCESSOR_REVISION' : '9a03' ,
'PROGRAMDATA' : 'C:\\ProgramData' ,
'PROGRAMFILES' : 'C:\\Program Files' ,
'PROGRAMFILES(X86)' : 'C:\\Program Files (x86)' ,
'PROGRAMW6432' : 'C:\\Program Files' ,
'PSMODULEPATH' : ' C : \ \ Program Files \ \ WindowsPowerShell \ \ Modules ;
C : \ \ Windows \ \ system32 \ \ WindowsPowerShell \ \ v1 . 0 \ \ Modules ' ,
'PUBLIC' : 'C:\\Users\\Public' ,
'PYCHARM_DISPLAY_PORT' : '63342' ,
'PYCHARM_HOSTED' : '1' , '
PYTHONIOENCODING ': ' UTF- 8 ' ,
'PYTHONPATH' : ' D : \ \ pythonProject ; D : / Program Files / JetBrains / PyCharm 2023.1 .4 /plugins/python/helpers/pycharm_matplotlib_backend;
D : / Program Files / JetBrains / PyCharm 2023.1 .4 /plugins/python/helpers/pycharm_display',
'PYTHONUNBUFFERED' : '1' ,
'SESSIONNAME' : 'Console' ,
'SYSTEMDRIVE' : 'C:' ,
'SYSTEMROOT' : 'C:\\Windows' ,
'TEMP' : 'C:\\Windows\\TEMP' ,
'TMP' : 'C:\\Windows\\TEMP' ,
'USERDOMAIN' : 'BLUE' ,
'USERDOMAIN_ROAMINGPROFILE' : 'BLUE' ,
'USERNAME' : 'blue' ,
'USERPROFILE' : 'C:\\Users\\blue' ,
'WINDIR' : 'C:\\Windows' ,
'ZES_ENABLE_SYSMAN' : '1' ,
'SERVER_NAME' : 'blue' ,
'GATEWAY_INTERFACE' : 'CGI/1.1' ,
'SERVER_PORT' : '8080' ,
'REMOTE_HOST' : '' ,
'CONTENT_LENGTH' : '' ,
'SCRIPT_NAME' : '' ,
'SERVER_PROTOCOL' : 'HTTP/1.1' ,
'SERVER_SOFTWARE' : 'WSGIServer/0.2' ,
'REQUEST_METHOD' : 'GET' ,
'PATH_INFO' : '/' ,
'QUERY_STRING' : '' ,
'REMOTE_ADDR' : '127.0.0.1' ,
'CONTENT_TYPE' : 'text/plain' ,
'HTTP_HOST' : '127.0.0.1:8080' ,
'HTTP_CONNECTION' : 'keep-alive' ,
'HTTP_CACHE_CONTROL' : 'max-age=0' ,
'HTTP_SEC_CH_UA' : ' "Microsoft Edge" ; v = "125" ,
"Chromium" ; v = "125" , "Not.A/Brand" ; v = "24" ' ,
'HTTP_SEC_CH_UA_MOBILE' : '?0' ,
'HTTP_SEC_CH_UA_PLATFORM' : '"Windows"' ,
'HTTP_DNT' : '1' ,
'HTTP_UPGRADE_INSECURE_REQUESTS' : '1' ,
'HTTP_USER_AGENT' :
' Mozilla / 5.0 ( Windows NT 10.0 ; Win64 ; x64 ) A
ppleWebKit / 537.36 ( KHTML , like Gecko ) Chrome / 125.0 .0 .0 Safari / 537.36 Edg / 125.0 .0 .0 ' ,
'HTTP_ACCEPT' : ' text / html , application / xhtml + xml , application / xml ;
q = 0.9 , image / avif , image / webp , image / apng , * / * ; q = 0.8 , application / signed-exchange ; v = b3 ; q = 0.7 ' ,
'HTTP_SEC_FETCH_SITE' : 'none' ,
'HTTP_SEC_FETCH_MODE' : 'navigate' ,
'HTTP_SEC_FETCH_USER' : '?1' ,
'HTTP_SEC_FETCH_DEST' : 'document' ,
'HTTP_ACCEPT_ENCODING' : 'gzip, deflate, br, zstd' ,
'HTTP_ACCEPT_LANGUAGE' : 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' ,
'HTTP_COOKIE' :
' csrftoken = PqreiKjPPgOJq09xzoB6hdkt5IDEOIr1 ;
sessionid = tmuiigt635exaogsh3c2k5fxgecvgcmk ' ,
'wsgi.input' : < _io . BufferedReader name = 504 > ,
'wsgi.errors' : < _io . TextIOWrapper name = '<stderr>' mode = 'w' encoding = 'utf-8' > ,
'wsgi.version' : ( 1 , 0 ) ,
'wsgi.run_once' : False ,
'wsgi.url_scheme' : 'http' ,
'wsgi.multithread' : False ,
'wsgi.multiprocess' : False ,
'wsgi.file_wrapper' : < class 'wsgiref.util.FileWrapper' > }
以下是对这些环境变量的一些简要解释 :
ALLUSERSPROFILE : 指向所有用户共享的配置文件的目录 .
APPDATA : 当前用户的应用程序数据目录 .
COMMONPROGRAMFILES : 指向程序文件 ( 公共 ) 的目录 , 通常是 32 位和 64 位应用共享的 .
COMMONPROGRAMFILES ( X86 ) : 指向 32 位应用程序的公共文件目录 .
COMPUTERNAME : 计算机的名称 .
COMSPEC : 指定命令解释器 ( 通常是cmd . exe ) 的位置 .
DRIVERDATA : 与驱动程序数据相关的目录 .
FPS_BROWSER_APP_PROFILE_STRING 和 FPS_BROWSER_USER_PROFILE_STRING :
与某种浏览器配置相关的字符串 ( 可能是特定于某个软件或库的 ) .
GETTEXTCLDRDIR : gettext库 ( 一个国际化和本地化库 ) 的目录 .
HOMEDRIVE 和 HOMEPATH : 定义用户的主目录 ( 如 C : \ Users \ blue ) .
IDEA_INITIAL_DIRECTORY : 与某种IDE ( 可能是IntelliJ IDEA或PyCharm ) 的初始目录有关 .
LOCALAPPDATA : 当前用户的应用程序本地数据目录 .
LOGONSERVER : 登录到的服务器名称 ( 在单用户系统中 , 这通常是计算机的名称 ) .
NUMBER_OF_PROCESSORS : 计算机上的处理器数量。
OS : 操作系统类型 ( 这里是Windows_NT ) .
PATH : 定义操作系统查找可执行文件的目录列表 .
PATHEXT : 可执行文件的扩展名列表 .
PROCESSOR_ARCHITECTURE : 处理器架构 ( 这里是AMD64 , 即 64 位 ) .
PROCESSOR_IDENTIFIER : 处理器的标识符 , 包括制造商 , 型号等信息 .
PROGRAMDATA , PROGRAMFILES , PROGRAMFILES ( X86 ) , PROGRAMW6432 : 与程序文件和数据相关的目录 .
PSMODULEPATH : PowerShell模块的路径 .
PUBLIC : 所有用户的公共目录 .
PYCHARM_DISPLAY_PORT 和 PYCHARM_HOSTED : 与PyCharm IDE的远程开发或调试相关的设置 .
PYTHONIOENCODING : Python的输入 / 输出编码设置 .
PYTHONPATH : Python解释器搜索模块的目录列表 .
SERVER_NAME 和 SERVER_PORT : 这两个变量分别表示接收请求的Web服务器的名称和端口号 .
对于本地开发环境 , SERVER_NAME可能是 'localhost' 或 '127.0.0.1, 而SERVER_PORT通常是您指定的端口, 如' 8080 ' .
REQUEST_METHOD : 表示HTTP请求的方法 , 如 'GET' , 'POST' , 'PUT' 等 . 这个信息对于确定如何响应请求至关重要 .
PATH_INFO : 表示请求的路径信息 , 即URL中服务器名称和端口号之后的部分 ( 不包括查询字符串 ) .
例如 , 在URL 'http://localhost:8080/hello?name=world' 中 , PATH_INFO的值是 '/hello' .
QUERY_STRING : 表示URL中的查询字符串部分 , 即?之后的部分 .
例如 , 在上面的URL中 , QUERY_STRING的值是 'name=world' .
REMOTE_ADDR : 表示发出请求的客户端的IP地址 .
对于本地开发 , 这通常是 '127.0.0.1' , 表示请求来自本地机器 .
HTTP_ * 开头的变量 : 这些变量包含了HTTP请求头的所有信息 .
例如,HTTP_HOST表示请求的主机名和端口号 , HTTP_USER_AGENT表示发出请求的浏览器或客户端的类型和版本 .
wsgi . * 开头的变量 : 这些是WSGI规范定义的特殊变量 , 提供了有关WSGI环境和请求的其他信息 .
例如 , wsgi . input是一个可读的输入流 , 用于读取HTTP请求的主体部分 ;
wsgi . errors是一个可写的输出流 , 用于记录错误信息 ;
wsgi . url_scheme表示URL的协议部分 ( 如 'http' 或 'https' ) .
这些环境变量在编写脚本 , 配置软件或进行系统级操作时都非常有用 ,
它们允许您引用特定的目录 , 配置或系统资源 , 而无需硬编码具体的路径或值 .
当浏览器发送一个HTTP请求时 , 无论是通过Socket直接接收还是通过WSGI服务器接收 , 底层传输的都是相同的字节流 .
但是 , Socket和WSGI在如何处理这些字节流上有所不同 , 这导致了它们 '解析' 出的信息在表现形式和易用性上的差异 .
Socket的解析 : 使用Socket直接接收数据时 , 会接收到一个原始的字节流 , 这个字节流包含了完整的HTTP请求 .
这需要自己编写代码来解析这个字节流 , 识别出HTTP请求的各个部分 ( 如请求行 , 请求头部 , 请求体等 ) , 并将这些信息提取出来 .
这个过程比较底层 , 要您了解HTTP协议的细节 .
WSGI的解析 : WSGI服务器 ( 如wsgiref ) 在接收到Socket传来的字节流后 ,
会负责解析这个字节流 , 并将其转换为一个WSGI环境字典 ( 也称为environ字典 ) .
这个环境字典包含了HTTP请求的所有相关信息 , 如请求方法 , 路径 , 头部 , 查询参数等 ,
以及服务器的一些环境信息 ( 如服务器的名称 , 端口号 , 客户端的IP地址等 ) .
这些信息都被封装在字典的键值对中 , 方便Web应用程序通过标准的接口来访问 .
WSGI服务器之所以能够解析出环境变量的信息 , 是因为它在解析HTTP请求时 , 不仅提取了HTTP请求本身的信息 ,
还根据服务器的配置和上下文环境生成了一些额外的信息 , 并将这些信息也包含在环境字典中 .
这些额外的信息对于Web应用程序来说是非常有用的 , 比如它们可以帮助应用程序确定请求的来源 , 目标地址 , 使用的协议等 .
以下是最应该关注的一些键 :
* 1. REQUEST_METHOD : 表示HTTP请求的方法 , 如GET , POST , PUT , DELETE等 .
这个信息决定了应用程序应该如何处理请求 .
* 2. PATH_INFO : 指示了请求的资源路径 .
这通常是URL中服务器名称和端口号之后的部分 , 并且不包括查询字符串 .
应用程序将使用这个信息来决定应该执行哪个操作或返回哪个资源 .
* 3. QUERY_STRING : 包含了URL中的查询字符串部分 , 即?之后的部分 .
这通常包含了一些键值对 , 用于传递参数给应用程序 .
* 4. REMOTE_ADDR : 表示发出请求的客户端的IP地址 .
这对于日志记录 , 安全审计或限制来自特定IP地址的请求等操作非常有用 .
* 5. HTTP_HOST : 客户端请求的主机名和端口号 .
这有助于确定应用程序应该如何响应 , 特别是在一个服务器上托管多个域名或应用程序时 .
* 6. wsgi . input : 对于POST或PUT请求 , 这个可读的输入流包含了请求的主体数据 , 需要读取这个流来获取客户端发送的数据 .
* 7. wsgi . errors : 这是一个可写的输出流 , 通常用于记录错误信息或调试信息 .
* 8. HTTP_USER_AGENT : 包含了发出请求的客户端的信息 , 如浏览器类型 , 版本等 .
这对于定制响应或进行用户代理特定的行为 ( 如重定向到移动版网站 ) 可能很有用 .
* 9. CONTENT_TYPE和CONTENT_LENGTH : 对于解析请求主体非常有用 .
CONTENT_TYPE指示了请求主体的媒体类型 ( 如application / json或text / plain ) .
CONTENT_LENGTH 提供了请求主体的长度 ( 以字节为单位 ) .
* 10. HTTP_ACCEPT : 客户端告诉服务器它可以接受哪些类型的响应内容 ( 如HTML , XML , JSON等 ) .
这有助于服务器根据客户端的偏好返回适当的响应 .
了解这些键的信息可以帮助您编写出更加健壮和灵活的Web应用程序 , 因为它们提供了关于HTTP请求的重要上下文信息 .
使用wsgiref . simple_server模块来创建一个基本的Web服务器 .
这个服务器会监听本地地址 127.0 .0 .1 的 8080 端口 , 并将接收到的HTTP请求交给run函数处理 .
run函数根据的请求路径的匹配结果 , 构建HTTP响应并将响应发送回客户端 .
from wsgiref. simple_server import make_server
def wsgi_app ( environ, start_response) :
status_200 = '200 OK'
status_404 = '404 File Not Found'
headers = [ ( 'Content-Type' , 'text/html' ) ]
path = environ. get( 'PATH_INFO' )
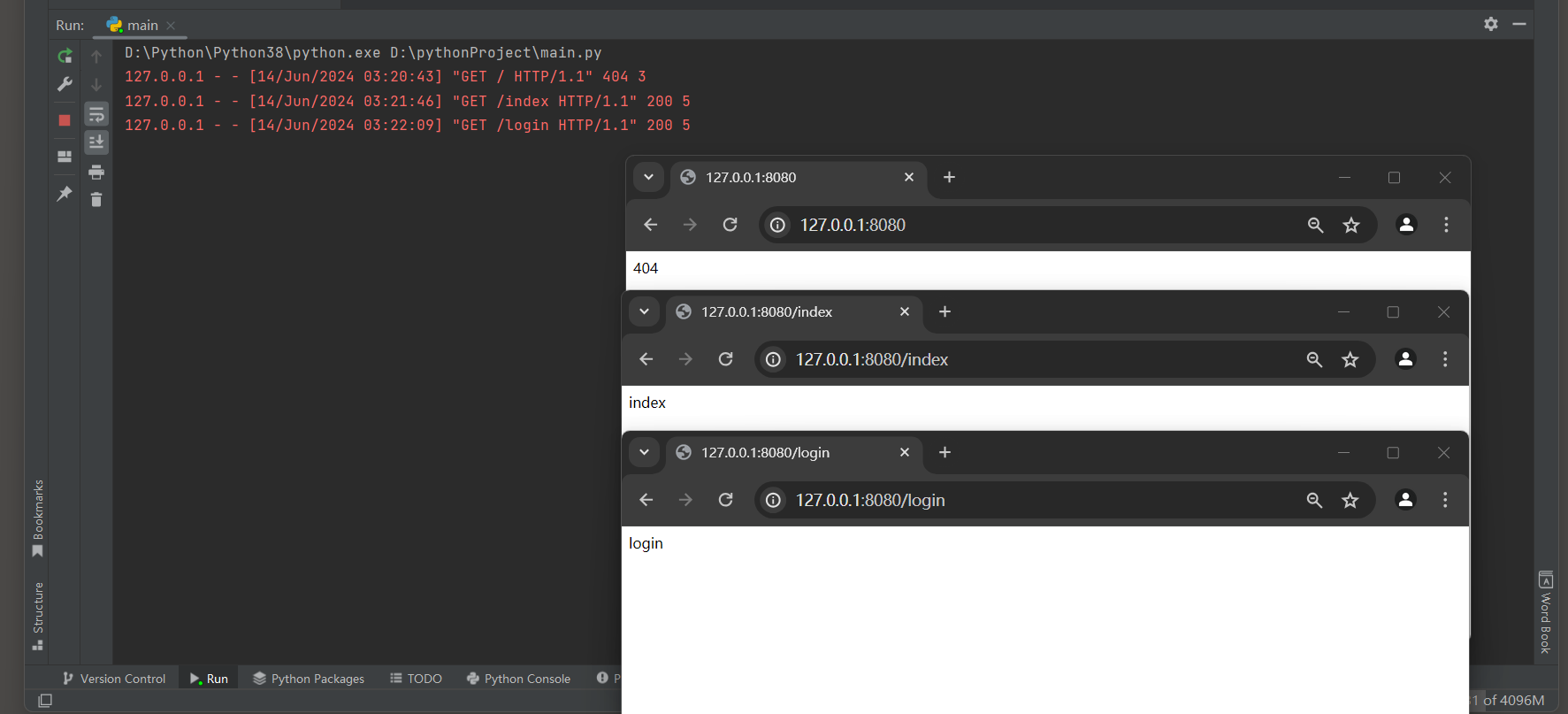
if path == '/index' :
start_response( status_200, headers)
return [ b'index' ]
elif path == '/login' :
start_response( status_200, headers)
return [ b'login' ]
else :
start_response( status_404, headers)
return [ b'404' ]
if __name__ == '__main__' :
server = make_server( '127.0.0.1' , 8080 , wsgi_app)
server. serve_forever( )
启动服务器 , 使用浏览器分别访问 :
127.0 .0 .1 : 8080
127.0 .0 .1 : 8080 /index
127.0 .0 .1 : 8080 /login
在Python中 , urllib . parse模块提供了用于解析URLs的实用函数 , 包括将查询字符串 ( query strings ) 解析为Python字典的parse_qs函数 .
查询字符串是URL中跟在?后面的部分 , 它包含了一系列由 & 分隔的键值对 ( key-value pairs ) ,
这些键值对通常用于表示HTTP GET或POST请求中的参数 .
例如 , 在 : https : / / example . com / search?q = python & page = 1 中 , 查询字符串是q = python & page = 1.
parse_qs函数可以将这样的查询字符串解析为一个Python字典 .
但是 , 请注意 , 由于一个键可能有多个值 ( 如使用表单提交多个复选框时 ) ,
所以parse_qs返回的字典的键对应的值是列表 ( list ) 而不是单个值 .
from urllib. parse import parse_qs
query_string = "q=python&page=1&color=red&color=blue"
params = parse_qs( query_string)
print ( params)
print ( params[ 'q' ] [ 0 ] )
for key, values in params. items( ) :
for value in values:
print ( f" { key} = { value} " )
在上面的示例中 , 可以看到parse_qs如何将查询字符串解析为一个字典 , 并处理具有多个值的键 .
当处理POST请求时 , 特别是当请求体包含表单数据时 , 需要从wsgi . input中读取数据 , 并根据Content-Type头部来决定如何解析这些数据 .
对于application / x-www-form-urlencoded类型的数据 , 可以使用urllib . parse . parse_qs或urllib . parse . parse_qsl来解析 .
POST中的数据结构也是键值对结构 , 并使用 & 分隔 , 如下图所示 :
from wsgiref. simple_server import make_server
from urllib. parse import parse_qs
def get_from_data ( environ) :
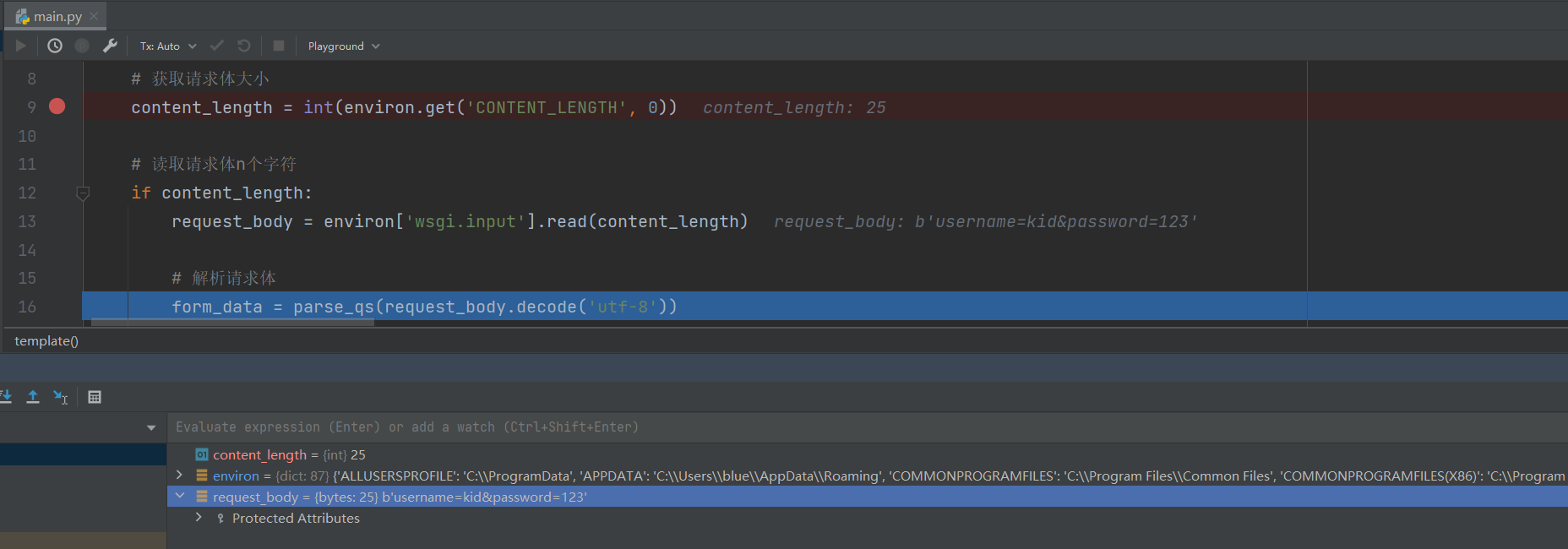
content_length = int ( environ. get( 'CONTENT_LENGTH' , 0 ) )
if content_length:
request_body = environ[ 'wsgi.input' ] . read( content_length)
form_data = parse_qs( request_body. decode( 'utf-8' ) )
return form_data
else :
return None
def wsgi_app ( environ, start_response) :
print ( '有人来了!!' )
status_200 = '200 OK'
headers = [ ( 'Content-Type' , 'text/html' ) ]
if environ. get( 'REQUEST_METHOD' ) == 'GET' :
params = parse_qs( environ. get( 'QUERY_STRING' ) )
print ( params)
if environ. get( 'REQUEST_METHOD' ) == 'POST' :
form_data = get_form_data( environ)
print ( form_data)
start_response( status_200, headers)
return [ b'ok' ]
if __name__ == '__main__' :
server = make_server( '127.0.0.1' , 8080 , wsgi_app)
server. serve_forever( )
GET请求访问 , 数据在url中 : http : / / 127.0 .0 .1 : 8080 /?name= 123 & pwd = 123
表单提交数据使用POST请求访问 , 数据不会出现在url中 , 设置form标签为 < form action = "http://127.0.0.1:8080" method = "post" > .
action属性为请求地址 , method属性为请求方式 .
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < formaction = " http://127.0.0.1:8080" method = " post" > < labelfor = " username" > </ label> < inputtype = " text" id = " username" name = " username" > < br> < labelfor = " password" > </ label> < inputtype = " text" id = " password" name = " password" > < br> < inputtype = " submit" value = " 提交" > </ form> </ body> </ html>
使用wsgiref . simple_server模块来创建一个基本的Web服务器 , 实现登录注册功能 .
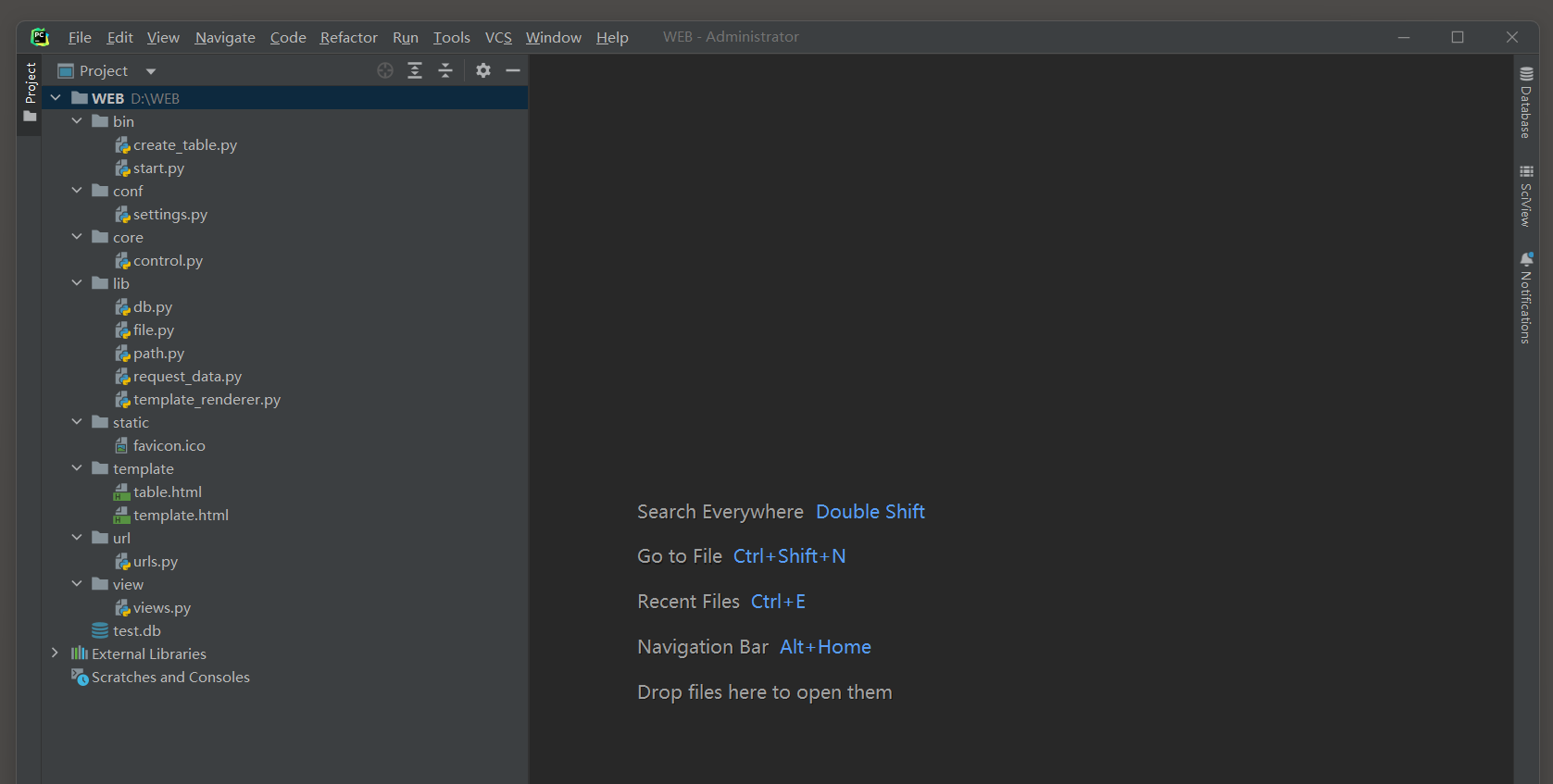
目录结构 :
Project
| --main . py 主程序
| --test . db 数据库文件
| --template . html 模板
| --table . html 表单
| --favicon . ico 头像
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> </ body> </ html>
< formaction = " " method = " post" > < labelfor = " username" > </ label> < inputtype = " text" id = " username" name = " username" > < br> < labelfor = " password" > </ label> < inputtype = " text" id = " password" name = " password" > < br> < inputtype = " submit" value = " 按键" > </ form>
from wsgiref. simple_server import make_server
import sqlite3
from urllib. parse import parse_qs
def get_form_data ( environ) :
content_length = int ( environ. get( 'CONTENT_LENGTH' , 0 ) )
if content_length:
request_body = environ[ 'wsgi.input' ] . read( content_length)
form_data = parse_qs( request_body. decode( 'utf-8' ) )
return form_data
else :
return None
def read_file ( file_name) :
with open ( file_name, 'r' , encoding= 'utf8' ) as f:
file_data = f. read( )
return file_data
def template ( title, content= None , button= None ) :
template_html = read_file( 'template.html' )
if not content:
content = read_file( 'table.html' )
content = content. replace( '按键' , button)
response_html = template_html. replace( '标题' , title)
response_html = response_html. replace( '内容' , content)
return response_html
def get_submit_data ( environ) :
form_data = get_form_data( environ)
if form_data:
username = form_data. get( 'username' )
if username:
username = username[ 0 ]
password = form_data. get( 'password' )
if password:
password = password[ 0 ]
return username, password
return None , None
def database_operations ( sql, commit= False ) :
conn = sqlite3. connect( 'test.db' )
cur = conn. cursor( )
res = cur. execute( * sql)
if commit:
conn. commit( )
fetchall = cur. fetchall( )
cur. close( )
conn. close( )
return res, fetchall
def register ( environ) :
if environ. get( 'REQUEST_METHOD' ) == 'GET' :
response_html = template( title= '注册页面' , button= '注册' )
return response_html. encode( 'utf8' )
else :
username, password = get_submit_data( environ)
if username and password:
sql = "SELECT username FROM user WHERE username = ?" , ( username, )
_, fetchall = database_operations( sql)
if fetchall:
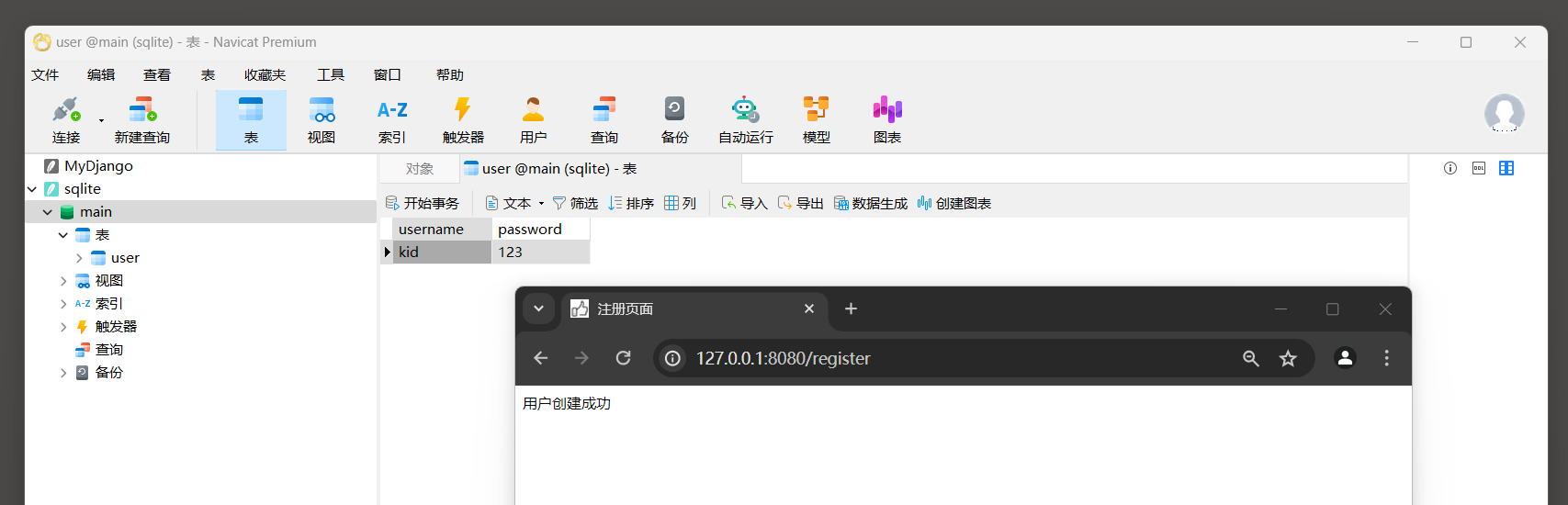
response_html = template( title= '注册页面' , content= '用户已经存在' )
return response_html. encode( 'utf8' )
else :
sql = "INSERT INTO user VALUES (?, ?)" , ( username, password)
res, _ = database_operations( sql, commit= True )
if res:
response_html = template( title= '注册页面' , content= '用户创建成功' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '注册页面' , content= '账号或密码为空!' )
return response_html. encode( 'utf8' )
def login ( environ) :
if environ. get( 'REQUEST_METHOD' ) == 'GET' :
response_html = template( title= '登录页面' , button= '登录' )
return response_html. encode( 'utf8' )
else :
username, password = get_submit_data( environ)
if username and password:
sql = "SELECT username, password FROM user WHERE username = ?" , ( username, )
_, fetchall = database_operations( sql, commit= True )
if fetchall:
user_info = fetchall[ 0 ]
if user_info == ( username, password) :
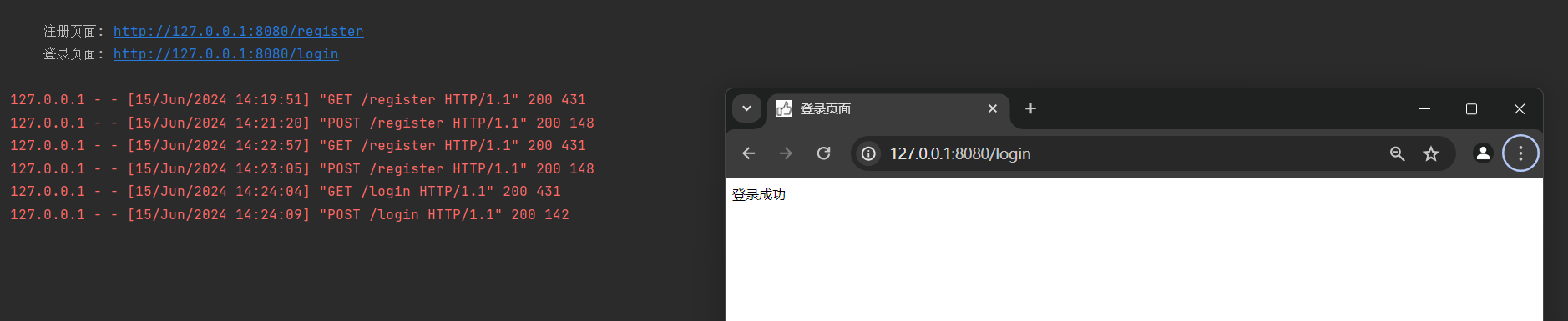
response_html = template( title= '登录页面' , content= '登录成功' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '登录页面' , content= '密码错误' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '登录页面' , content= '用户不存在, 请注册!' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '登录页面' , content= '账号或密码为空!' )
return response_html. encode( 'utf8' )
def favicon ( environ) :
with open ( 'favicon.ico' , 'rb' ) as f:
favicon_date = f. read( )
return favicon_date
def error ( environ) :
response_html = template( title= '404页面' , content= '404 访问资源部存在' )
return response_html. encode( 'utf8' )
urls = {
'/register' : register,
'/login' : login,
'/favicon.ico' : favicon,
}
def wsgi_app ( environ, start_response) :
status_200 = '200 OK'
status_404 = '404 File Not Found'
headers = [ ( 'Content-Type' , 'text/html' ) ]
path = environ. get( 'PATH_INFO' )
func = urls. get( path, None )
if func:
res = func( environ)
start_response( status_200, headers)
else :
res = error( environ)
start_response( status_404, headers)
return [ res]
if __name__ == '__main__' :
server = make_server( '127.0.0.1' , 8080 , wsgi_app)
print ( """
注册页面: http://127.0.0.1:8080/register
登录页面: http://127.0.0.1:8080/login
""" )
server. serve_forever( )
这个Python程序定义了一个简单的WSGI应用程序 , 它使用字典来映射URL路径到相应的处理函数 .
以下是该程序的大致描述 :
* 1. 定义URL映射字典 : 使用一个名为urls的字典来映射URL路径到处理函数 .
例如 , 当客户端请求 / register路径时 , register函数将被调用 ;
当请求 / login时 , login函数将被调用 , 依此类推 .
* 2. 定义WSGI应用程序 : wsgi_app函数是WSGI应用程序的核心 .
它接受两个参数 : environ ( 一个包含CGI环境变量的字典 ) 和start_response ( 一个可调用的对象 , 用于设置HTTP响应的状态码和头部 ) .
* 3. 设置响应状态码和头部 : 定义了两个状态码 : status_200 ( 成功响应 ) 和status_404 ( 未找到文件 ) .
定义了一个HTTP头部列表headers , 其中包含一个 'Content-Type' 头部 , 其值为 'text/html' .
* 4. 获取请求路径 : 从environ字典中获取 'PATH_INFO' 键的值 , 该值表示客户端请求的URL路径 .
* 5. 获取处理函数 : 使用urls . get ( path , None ) 从urls字典中根据请求路径获取相应的处理函数 .
如果路径不存在于字典中 , 则返回None .
* 5. 处理请求 : 如果找到了处理函数 ( 即func不为None ) , 则调用该函数并传入environ作为参数 .
然后将响应状态码设置为status_200 , 并调用start_response来设置HTTP响应的状态码和头部 .
如果没有找到处理函数 ( 即func为None ) , 则调用一个名为error的函数 , 然后将响应状态码设置为status_404 , 并调用start_response .
* 6. 返回响应体 : 将处理函数返回值作为响应体返回 .
注意 , 由于WSGI规范要求响应体必须是一个可迭代对象 , 因此即使是一个字符串 , 也需要将其放入一个列表中返回 .
GET请求 : 当用户通过浏览器访问注册 / 登录页面时 , 通常会发送一个GET请求 .
在这个函数中 , 如果接收到的是GET请求 , 那么会调用template的函数生成的HTML页面返回给客户端 .
POST请求 : 当用户在注册 / 登录页面填写了用户名和密码 , 并点击了登录按钮后 , 浏览器会向服务器发送一个POST请求 , 包含用户提交的数据 .
首先 , 通过调用get_submit_data ( environ ) 函数从POST请求中提取用户提交的用户名和密码 .
接着 , 进行非空判断 , 确保用户名和密码都已填写 .
如果用户名和密码都不为空 , 那么会连接到SQLite数据库 , 并查询用户表中是否存在匹配的用户名和密码 .
如果数据库中存在匹配的用户名和密码 , 那么会返回一个登录成功的页面 ;
如果不匹配 , 会返回一个账号密码错误的页面 .
如果用户名或密码为空 , 则会返回一个提示账号或密码为空的页面 .
启动程序访问注册页面 : http : / / 127.0 .0 .1 : 8080 /register , 填写数据提交 .
再次访问注册页面 : http : / / 127.0 .0 .1 : 8080 /register , 填写存在的数据 ( 模拟用户名称存在的场景 ) .
程序访问登录页面 : http : / / 127.0 .0 .1 : 8080 /register , 填写正确的数据并提交 .
再次程序访问登录页面 : http : / / 127.0 .0 .1 : 8080 /register , 填写错误的数据并提交 .
情况 1 : 用户不存在
情况 2 : 账号存在密码错误
情况 3 : 提交空数据
动态网页和静态网页是网页设计和开发中的两个基本概念 , 它们的主要区别在于网页内容是如何生成和显示的 .
静态网页 : 静态网页是预先创建并存储在服务器上的HTML文件 .
这些文件包含了固定的内容 , 如文本 , 图片 , 视频等 , 这些内容在发布到服务器后通常不会改变 ( 除非手动更新文件 ) .
当用户请求静态网页时 , 服务器会直接发送存储的HTML文件给用户的浏览器进行渲染和显示 .
特点如下 :
* 1. 内容固定 : 一旦发布 , 内容就不会自动改变 .
* 2. 交互有限 : 用户与静态网页的交互通常是通过点击链接跳转到其他页面或表单提交来实现的 .
* 3. 服务器负担轻 : 因为服务器只是发送预先存储的文件 , 所以处理请求的效率很高 .
* 4. 易于优化 : 因为内容固定 , 所以搜索引擎优化 ( SEO ) 和缓存优化相对容易 .
动态网页 : 动态网页则是根据用户的请求或特定的条件动态生成的HTML内容 .
这些网页通常包含了服务器端脚本 ( 如PHP , ASP . NET , Node . js等 ) 和数据库 ( 如MySQL , MongoDB等 ) ,
用于处理用户输入 , 存储和检索数据 , 并根据这些数据动态生成HTML内容 .
特点如下 :
* 1. 内容可变 : 根据用户请求或数据库中的数据动态生成内容 .
* 2. 交互丰富 : 通过服务器端脚本和数据库 , 可以实现更复杂的用户交互 , 如在线购物 , 用户登录 , 数据搜索等 .
* 3. 服务器负担重 : 因为服务器需要处理用户请求 , 执行脚本 , 访问数据库等操作 , 所以处理请求的效率相对较低 .
* 4. 安全性要求高 : 因为涉及到用户输入和数据库操作 , 所以需要采取更多的安全措施来防止SQL注入 , 跨站脚本攻击 ( XSS ) 等安全问题 .
总结 : 静态网页和动态网页各有优缺点 , 适用于不同的场景 .
对于内容固定 , 交互简单的网站 , 静态网页可能更合适 ; 而对于需要动态生成内容 , 实现复杂交互的网站 , 动态网页则更具优势
页面静态化是一种将动态网页转换为静态HTML页面的技术 .
将原本由服务器端动态生成的网页内容 ( 如JSP , PHP等 ) , 转化为静态的HTML文件 , 并存储在服务器上 , 供用户直接访问 .
页面静态化的方法有多种 , 其中常见的包括 :
* 1. 直接生成 : 在服务器端直接生成HTML文件 , 并保存到服务器的文件系统中 .
当用户请求该页面时 , 服务器直接发送静态的HTML文件给用户 , 而不再执行动态脚本 .
* 2. 通过HTTP请求获取 : 使用编程语言 ( 如PHP ) 中的相关函数 ( 如file_get_contents或curl ) ,
向服务器发送HTTP请求 , 获取动态页面的HTML内容 , 然后将这些内容保存到本地文件中 .
页面静态化具有以下优点 :
* 1. 提高速度 : 由于静态页面不需要在服务器端执行动态脚本和查询数据库 , 因此访问速度更快 .
对于访问量大的网站 , 这可以显著提高用户体验 .
* 2. 搜索引擎友好 : 搜索引擎更喜欢静态网页 , 因为它们更容易被抓取和索引 . 这有助于提高网站的SEO排名 .
* 3. 安全性 : 静态网页不容易被黑客攻击 , 因为它们不包含敏感数据和执行代码 .
* 4. 稳定性 : 如果后台程序或数据库出现问题 , 静态网页仍然可以正常访问 , 这保证了网站的稳定性 .
页面静态化也存在一些缺点 :
* 1. 交互性差 : 由于静态页面不包含动态内容 , 因此无法实现复杂的用户交互功能 .
* 2. 开发复杂度 : 增加了网站的开发复杂度 , 因为需要同时维护动态和静态两种页面 .
* 3. 占用硬盘空间 : 静态页面会占用更多的服务器硬盘空间 , 尤其是在页面数量庞大的情况下 .
* 4. 不灵活 : 静态化操作需要手动或自动触发 , 不能实时反映数据的变化 .
页面静态化适用于以下场景 :
内容更新频率低 : 如果网站的内容更新频率不高 , 或者大部分内容都是固定的 , 那么可以考虑使用页面静态化来提高访问速度 .
搜索引擎优化 : 对于需要提高SEO排名的网站 , 页面静态化是一个有效的手段 .
提高安全性 : 对于安全性要求较高的网站 , 如金融 , 电商等 , 可以使用页面静态化来减少潜在的安全风险 .
总之 , 页面静态化是一种在特定场景下提高网站性能和安全性的有效技术 .
在实际应用中 , 需要根据网站的具体需求来选择是否使用页面静态化技术 .
页面伪静态是一种技术 , 它使得动态页面在外观上和行为上类似于静态页面 , 但实际上仍然是动态生成的 .
这种技术主要用于提高网站的搜索引擎优化 ( SEO ) 效果 , 改善用户体验和安全性 .
页面伪静态是指将动态页面 ( 如ASP , PHP , JSP等脚本程序生成的页面 ) 通过服务器端的配置和规则 , 模拟出静态页面的效果 .
虽然从URL结构和页面名称上看 , 伪静态页面和静态页面相似 , 但实际上它们仍然是动态生成的 .
页面伪静态的实现方法有多种 , 包括但不限于以下几种 :
* 1. URL重写 : 通过修改服务器 ( 如Apache , Nginx等 ) 的配置文件 , 使用URL重写技术将动态的URL转换成静态的URL .
例如 , 将动态URL : https : / / www . example . com / index . php?id = 1 转换成静态URL https : / / www . example . com / article / 1. html .
* 2. Apache服务器 : 在 . htaccess文件中添加RewriteRule规则来实现伪静态 .
* 3. Nginx服务器 : 在Nginx的配置文件中定义location规则 , 使用正则表达式匹配URL并进行重写 .
* 4. 框架伪静态 : 利用一个静态框架页面 , 将所有的动态页面内容添加到框架页面内 .
这种方法可以从地址栏中看出 , 如果网站全部的URL地址都一样 , 那就说明可能采用了框架伪静态 .
* 5. 文件组件或组件转换 : 例如使用FSO文件组件或Intelligencia . UrlRewriter . dll组件 ,
将动态页面 ( 如 . aspx ) 的后缀显示为静态页面的后缀 ( 如 . htm或 . html ) .
* 6. URL参数解析 : 在服务器端脚本 ( 如PHP ) 中 , 通过解析URL参数的方式实现伪静态页面 .
获取URL中的参数 , 并根据参数值来动态加载相应的页面内容 .
优点 :
* 1. 提高SEO效果 : 伪静态页面易于被搜索引擎收录 , 因为它们具有类似于静态页面的URL结构 .
* 2. 改善用户体验 : 伪静态页面具有更简洁 , 易记的URL , 提高了用户体验 .
* 3. 安全性提升 : 通过隐藏或加密URL地址 , 使黑客难以找到真实的动态页面 , 同时降低了动态文件所需的权限 , 减少了木马注入的风险 .
* 4. 维护方便 : 伪静态页面具有自动更新和变化的能力 , 减少了维护量 .
缺点 :
* 1. CPU使用率上升 : 由于伪静态页面需要通过服务器端的规则进行转换 , 因此会增加服务器的CPU使用率 .
* 2. 可能增加响应时间 : 在高流量的情况下 , 伪静态页面的转换可能会导致服务器响应时间的增加 .
总结 : 页面伪静态是一种将动态页面模拟成静态页面的技术 , 旨在提高网站的SEO效果 , 改善用户体验和安全性 .
通过URL重写 , 框架伪静态 , 文件组件或组件转换以及URL参数解析等方法可以实现页面伪静态 .
虽然伪静态页面具有诸多优点 , 但也需要注意其可能带来的服务器负担和响应时间增加的问题 .
Jinja2是一个Python的模板引擎 , 它用于将动态内容嵌入到静态文件中 , 生成HTML , XML或其他任何基于文本的格式 .
Jinja2提供了很多控制结构和过滤器 , 帮助你轻松地创建复杂的模板 .
( 这里只简单讲解 , 后续会重新讲解 . )
如果还没有安装Jinja2 , 可以使用pip来安装 : pip install Jinja2 .
以下是Jinja2模板的一些基本语法 :
* 1. 变量 : 使用双大括号 { { variable_name } } 来在模板中插入变量 .
Jinja2会将变量的值转换为字符串 ( 除非在过滤器中指定了不同的行为 ) .
< p> </ p> * 2. 使用 if , elif 和 else 来创建条件语句 , 结构如下 :
{% if user %}
Hello, {{ user }}!
{% elif guest %}
Hello, Guest!
{% else %}
Hello, world!
{% endif %}
* 3. 使用 for 循环来遍历列表 , 元组 , 字典或集合 .
< ul> < li> </ li> </ ul> < dt> </ dt> < dd> </ dd> </ dl> 以下是如何使用Jinja2模块的基本步骤 :
* 1. 编写test模板 , 在模板中可以使用Jinja2的特殊语法来插入变量和逻辑 .
<! doctype html > < htmllang = " en" > < head> < title> </ title> </ head> < body> < h1> </ h1> < ul> < li> </ li> </ ul> </ body> </ html> 在上面的模板中 , { { title } } , { { heading } } , { { paragraph } } 和 { { item } } 是变量 ,
{ % for item in items % } 和 { % endfor % } 是控制结构 .
* 2. 在Python中使用Jinja2 , 在Python脚本中加载模板 , 并使用数据来渲染模板 .
from jinja2 import Environment
from jinja2 import FileSystemLoader
env = Environment( loader= FileSystemLoader( './' ) )
template = env. get_template( 'test.html' )
data = {
'title' : '网站名称' ,
'heading' : '标题: 欢迎来到我的网站' ,
'items' : [ '段落 1' , '段落 2' , '段落 3' ] ,
}
output = template. render( data)
print ( output)
在这个例子中 , 首先从jinja2模块导入Environment和FileSystemLoader .
然后 , 创建一个Environment对象 , 并指定模板文件的加载器 .
接下来 , 使用get_template ( ) 方法加载模板文件 .
然后 , 定义了一个包含要传递给模板的数据的字典 .
最后 , 使用render ( ) 方法将数据传递给模板 , 并打印出渲染后的HTML .
<! doctype html > < htmllang = " en" > < head> < title> </ title> </ head> < body> < h1> </ h1> < ul> < li> </ li> < li> </ li> < li> </ li> </ ul> </ body> </ html> Template模块是Python开发中一个常用的模板系统 .
Jinja2基于Python模板引擎 , 主要用于生成配置文件或HTML页面等基于文本的格式 .
使用方式 :
* 1. 创建一个Template对象 , 通常是通过传递一个字符串 ( 这个字符串就是模板的内容 ) 给Template类的构造函数 .
* 2. 使用render ( ) 方法来渲染模板 , 这个方法接受一个字典作为参数 ,
字典的键对应于模板中的变量名 , 值则会被插入到模板中以替换对应的变量 .
* 3. render ( ) 方法返回一个字符串 , 这个字符串是模板渲染后的结果 .
from jinja2 import Template
data_dic = {
'title' : '网站名称' ,
'heading' : '标题: 欢迎来到我的网站' ,
'username' : 'kid' ,
'age' : 18 ,
'hobby' : 'read'
}
with open ( 'test2.html' , mode= 'rt' , encoding= 'utf-8' ) as f:
str_html = f. read( )
tmp = Template( str_html)
res = tmp. render( data= data_dic)
print ( res)
render ( ) 方法 : 来填充模板中的变量 .
可以将一个字典 , 字典子类或关键字参数传递给该方法 , 以在模板渲染时提供上下文数据 .
在模板中 , 变量可以按字典取值 , 对象获取属性的方式使用 .
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> < p> </ p> < p> </ p> < p> </ p> < p> </ p> </ body> </ html>
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> < p> </ p> < p> </ p> < p> </ p> < p> </ p> </ body> </ html> render ( ) 方法推荐的使用方式 : res = tmp . render ( * * data_dic )
使用 * * data_dic是更简洁 , 更常用的方法 , 因为它会自动将字典的键-值对解包为函数的关键字参数 .
from jinja2 import Template
data_dic = {
'title' : '网站名称' ,
'heading' : '标题: 欢迎来到我的网站' ,
'username' : 'kid' ,
'age' : 18 ,
'hobby' : 'read'
}
with open ( 'test2.html' , mode= 'rt' , encoding= 'utf-8' ) as f:
str_html = f. read( )
tmp = Template( str_html)
res = tmp. render( ** data_dic)
print ( res)
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> < p> </ p> < p> </ p> < p> </ p> </ body> </ html>
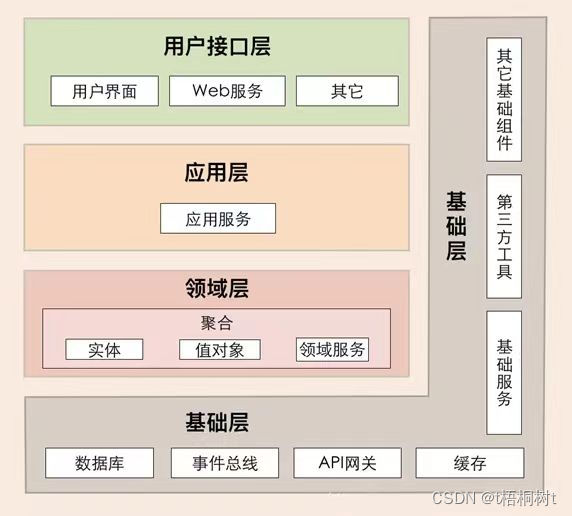
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h1> </ h1> < p> </ p> < p> </ p> < p> </ p> </ body> </ html> 将原本集中在一个或多个文件中的代码 , 按照功能 , 模块或组件进行分离 , 形成多个独立的代码文件 .
每个模块都包含完成其功能的必要代码 , 并且与其他模块通过接口进行交互 .
拆分后 , 每个文件只包含特定的功能或模块 , 使得代码结构更加清晰 , 易于理解和修改 .
将Web应用程序的不同部分进行拆分和封装 , 程序结构如下 :
* 1. 控制层 ( Control Layer ) : 使用control . py文件来编写控制逻辑 .
这个文件通常包含处理HTTP请求和响应的控制函数或类 .
* 2. 路由层 ( Routing Layer ) : 使用urls . py文件来定义URL模式与视图函数之间的映射关系 .
根据URL中的 '路径' 部分 , 返回不同的信息或调用相应的视图函数 .
* 3. 视图层 ( View Layer ) : 使用views . py文件来编写业务逻辑 .
这个文件包含处理特定请求并返回响应数据 ( 可能是HTML , JSON等 ) 的视图函数 .
* 4. 模板层 ( Template Layer ) : 在templates文件夹中存储HTML前端页面 .
这些页面通常由视图函数渲染并返回给客户端 .
当需要为Web应用程序添加新功能时 , 只需按照以下步骤进行 :
* 1. 在urls . py中定义新的路由 : 为新功能定义一个新的URL模式 , 并将其映射到相应的视图函数 .
* 2. 在views . py中编写新的业务逻辑 : 编写一个新的视图函数来处理与新功能相关的业务逻辑 .
这个函数应该根据请求执行必要的操作 , 并返回一个适当的响应 .
* 3. 在template下创建模板 : 如果新功能需要渲染HTML页面 , 可以在templates文件夹中创建一个新的模板文件 .
这个模板文件将包含HTML标记和模板变量 , 用于在视图函数中动态插入数据 .
通过这种方式 , 可以保持Web应用程序的结构清晰和模块化 , 便于后续的开发和维护 .
对面条版 ( spaghetti code , 即混乱 , 难以维护的代码 ) 进行重构 , 并引入适当的目录规范 .
Project 项目的根目录
| --bin 存放可执行脚本的目录
| | --create_table . py 数据库创建 , 表格创建 ( 第一次启动项目前执行 , 创建user表 )
| | --start . py 启动项目的脚本
| --conf 存放配置文件的目录
| | --settings . py 项目的主要配置文件,包含数据库连接信息
| --core 存放项目核心逻辑的目录
| | --control . py 包含项目的路由控制逻辑或其他核心功能
| --lib 存放项目所需的各种库或工具的目录
| | --db . py 数据库操作的封装
| | --file . py 文件操作的封装
| | -- path . py 处理文件路径操作的模块
| | --request_data . py 处理HTTP请求数据的逻辑
| | --template_renderer . py 模板渲染的逻辑
| --static 存放静态文件的目录 ( 通常还会包含CSS , JavaScript , 图片等其他静态资源 )
| | --favicon . ico 网站的图标
| --template 存放HTML模板的目录
| | --table . html 表单模板
| | --template . html 主模板
| --url 存放URL路由配置的目录
| | --urls . py 定义URL到视图函数的映射
| --view 存放视图函数的目录
| | --views . py 包含处理HTTP请求并返回响应的视图函数
| --test . db 项目的数据库文件
import sqlite3
conn = sqlite3. connect( 'test.db' )
cur = conn. cursor( )
cur. execute( '''CREATE TABLE user
(username varchar(12), password varchar(12)''' )
conn. close( )
import os
import sys
from wsgiref. simple_server import make_server
from core. control import wsgi_app
BASE_PATH = os. path. dirname( os. path. dirname( __file__) )
sys. path. append( BASE_PATH)
if __name__ == '__main__' :
server = make_server( '127.0.0.1' , 8080 , wsgi_app)
print ( """
注册页面: http://127.0.0.1:8080/register
登录页面: http://127.0.0.1:8080/login
""" )
server. serve_forever( )
import os
BATH_PATH = os. path. dirname( os. path. dirname( __file__) )
static_path = os. path. join( BATH_PATH, 'static' )
templates_path = os. path. join( BATH_PATH, 'template' )
db_path = os. path. join( BATH_PATH, 'test.db' )
from url. urls import urls
from view. views import error
def wsgi_app ( environ, start_response) :
status_200 = '200 OK'
status_404 = '404 File Not Found'
headers = [ ( 'Content-Type' , 'text/html' ) ]
path = environ. get( 'PATH_INFO' )
func = urls. get( path, None )
if func:
res = func( environ)
start_response( status_200, headers)
else :
res = error( environ)
start_response( status_404, headers)
return [ res]
import sqlite3
from conf. settings import db_path
def database_operations ( sql, commit= False ) :
conn = sqlite3. connect( db_path)
cur = conn. cursor( )
print ( )
res = cur. execute( * sql)
if commit:
conn. commit( )
fetchall = cur. fetchall( )
cur. close( )
conn. close( )
return res, fetchall
from conf. settings import os, templates_path, static_path
def get_html_path ( html_name) :
html_path = os. path. join( templates_path, html_name)
return html_path
def get_favicon_path ( ) :
favicon_path = os. path. join( static_path, 'favicon.ico' )
return favicon_path
from conf. settings import os, templates_path, static_path
def get_html_path ( html_name) :
html_path = os. path. join( templates_path, html_name)
return html_path
def get_favicon_path ( ) :
favicon_path = os. path. join( static_path, 'favicon.ico' )
return favicon_path
from urllib. parse import parse_qs
def get_form_data ( environ) :
content_length = int ( environ. get( 'CONTENT_LENGTH' , 0 ) )
if content_length:
request_body = environ[ 'wsgi.input' ] . read( content_length)
form_data = parse_qs( request_body. decode( 'utf-8' ) )
return form_data
else :
return None
def get_submit_data ( environ) :
form_data = get_form_data( environ)
if form_data:
username = form_data. get( 'username' )
if username:
username = username[ 0 ]
password = form_data. get( 'password' )
if password:
password = password[ 0 ]
return username, password
return None , None
from lib. file import read_file
def template ( title, content= None , button= None ) :
template_html = read_file( 'template.html' )
if not content:
content = read_file( 'table.html' )
content = content. replace( '按键' , button)
response_html = template_html. replace( '标题' , title)
response_html = response_html. replace( '内容' , content)
return response_html
头像文件名字 : favicon . ico
< formaction = " " method = " post" > < labelfor = " username" > </ label> < inputtype = " text" id = " username" name = " username" > < br> < labelfor = " password" > </ label> < inputtype = " text" id = " password" name = " password" > < br> < inputtype = " submit" value = " 按键" > </ form>
< htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> </ body> </ html>
from view. views import register, login, favicon
urls = {
'/register' : register,
'/login' : login,
'/favicon.ico' : favicon,
}
from lib. template_renderer import template
from lib. request_data import get_submit_data
from lib. db import database_operations
from lib. file import read_favicon
def register ( environ) :
if environ. get( 'REQUEST_METHOD' ) == 'GET' :
response_html = template( title= '注册页面' , button= '注册' )
return response_html. encode( 'utf8' )
else :
username, password = get_submit_data( environ)
if username and password:
sql = "SELECT username FROM user WHERE username = ?" , ( username, )
_, fetchall = database_operations( sql)
if fetchall:
response_html = template( title= '注册页面' , content= '用户已经存在' )
return response_html. encode( 'utf8' )
else :
sql = "INSERT INTO user VALUES (?, ?)" , ( username, password)
res, _ = database_operations( sql, commit= True )
if res:
response_html = template( title= '注册页面' , content= '用户创建成功' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '注册页面' , content= '账号或密码为空!' )
return response_html. encode( 'utf8' )
def login ( environ) :
if environ. get( 'REQUEST_METHOD' ) == 'GET' :
response_html = template( title= '登录页面' , button= '登录' )
return response_html. encode( 'utf8' )
else :
username, password = get_submit_data( environ)
if username and password:
sql = "SELECT username, password FROM user WHERE username = ?" , ( username, )
_, fetchall = database_operations( sql, commit= True )
if fetchall:
user_info = fetchall[ 0 ]
if user_info == ( username, password) :
response_html = template( title= '登录页面' , content= '登录成功' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '登录页面' , content= '密码错误' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '登录页面' , content= '用户不存在, 请注册!' )
return response_html. encode( 'utf8' )
else :
response_html = template( title= '登录页面' , content= '账号或密码为空!' )
return response_html. encode( 'utf8' )
def favicon ( environ) :
favicon_date = read_favicon( )
return favicon_date
def error ( environ) :
response_html = template( title= '404页面' , content= '404 访问资源部存在' )
return response_html. encode( 'utf8' )